





Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| The student will learn alternatives for relational databases for storing Big Data, the type of data that includes unstructured and semi-structured data that is not well suited for traditional databases. | The student will be able to list and explain various types of Big Data. |
| The student will be able to list and explain the problems associated with Big Data. | |
| The student will be able to list and explain the characteristics of Big Data. | |
| The student will be able to list and explain emerging Big Data technologies. |
Section 1: Overview
The amount of data being collected has been growing exponentially in size and complexity.
- Traditional relational databases are good at managing structured data but are not well suited to managing and processing the amounts and types of data being collected in today's business environment.
- Advances in technology have led to a vast array of user-generated data and machine-generated data that can spur growth in specific areas.
Web data in the form of browsing patterns, purchasing histories, customer preferences, behavior patterns, and social media data from sources such as Facebook, Twitter, and Linkedln have inundated organizations with combinations of structured and unstructured data.
- In addition, mobile technologies such as smartphones and tablets, plus sensors of all types – GPS, RFID systems, weather sensors, biomedical devices, space research probes, car and aviation black boxes – as well as other Internet and cellular-connected devices, have created new ways to automatically collect massive amounts data in multiple formats (text, pictures, sound, video, etc.).
- The amount of data being collected grows exponentially every day. According to IBM, "Every day we create 2.5 quintillion bytes of data – so much that 90 percent of the data in the world today has been created in the last two years alone."
Section 2: Issues
The problem is that the relational approach does not always match the needs of organizations with Big Data challenges.
- It is not always possible to fit unstructured, social media and sensor-generated data into the conventional relational structure of rows and columns.
- Adding millions of rows of multiformat (structured and nonstructured) data on a daily basis will inevitably lead to the need for more storage, processing power, and sophisticated data analysis tools that may not be available in the relational environment.
- The type of high-volume implementations required in the RDBMS environment for the Big Data problem comes with a hefty price tag for expanding hardware, storage, and software licenses.
- Data analysis based on OLAP tools has proven to be very successful in relational environments with highly structured data. However, mining for usable data in the vast amounts of unstructured data collected from web sources requires a different approach.
Section 3: Big Data Characteristics
Big Data generally refers to a set of data that displays the characteristics of volume, velocity, and variety (the "3 Vs") to an extent that makes the data unsuitable for management by a relational database management system.
Note that the "3 Vs" have been expanded to "5 Vs" (or more).
- Volume – the quantity of data to be stored.
- Velocity – the speed at which data is entering the system.
- Variety – the variations in the sources and formats of the data to be stored.
- Veracity – the trustworthiness of the data.
- Value – insights that are generated from the data are based on accurate data and lead to measurable improvements.
There are no specific values associated with these characteristics. The issue is that the characteristics are present to such an extent that the current relational database technology struggles with managing the data.
Volume
Volume, the quantity of data to be stored, is a key characteristic of Big Data because the storage capacities associated with Big Data are extremely large.
As the quantity of data needing to be stored increases, the need for larger storage devices increases as well. When this occurs, systems can either scale up or scale out.
-
Scaling up is keeping the same number of systems, but migrating
each system to a larger system: for example, changing from a server
with 16 CPU cores and a 1 terabyte storage system to a server with 64 CPU
cores and a 100 terabyte storage system
- Scaling up involves moving to larger and faster systems, but there are limits to how large and fast a single system can be.
- Further, the costs of these high-powered systems increase at a dramatic rate.
-
Scaling out means that when the workload exceeds the capacity of a
server, the workload is spread out across a number of servers. This
is also referred to as clustering – creating a cluster of
low-cost servers to share a workload.
- This can help to reduce the overall cost of the computing resources since it is cheaper to buy ten 100 terabyte storage systems than it is to buy a single 1 petabyte storage system.
Velocity
Velocity refers to the rate at which new data enters the system as well as the rate at which the data must be processed.
Rate at which new data enters the system
The issues of velocity mirror those of volume.
- For example, retail stores used to capture only the data about the final transaction of a customer making a purchase.
- A retailer like Amazon captures not only the final transaction, but every click of the mouse in the searching, browsing, comparing, and purchase process.
- Instead of capturing one event (the final sale) in a 20-minute shopping experience, it might capture data on 30 events during that 20-minute time frame – a 30× increase in the velocity of the data.
Other newer technologies, such as RFID, GPS, and NFC, add new layers of data-gathering opportunities that often generate large amounts of data that must be stored in real-time.
- For example, RFID tags can be used to track items for inventory and warehouse management.
- The tags do not require line-of-sight between the tag and the reader, and the reader can read hundreds of tags simultaneously while the products are still in boxes.
- Instead of a single record for tracking a given quantity of a product being produced, each individual product is tracked, creating an increase of several orders of magnitude in the amount of data being delivered to the system at any one time.
Rate at which the data must be processed
The velocity of processing can be broken down into two categories.
-
Stream processing
- Stream processing focuses on input processing, and it requires analysis of the data stream as it enters the system.
-
In some situations, large volumes of data can enter the system at such
a rapid pace that it is not feasible to try to store all of the data, but
rather the data must be processed and filtered as it enters the system to
determine which data to keep and which data to discard.
- For example, at the CERN Large Hadron Collider, the largest and most powerful particle accelerator in the world, experiments produce about 600 terabytes per second of raw data.
- Scientists have created algorithms to decide ahead of time which data will be kept. These algorithms are applied in a two-step process to filter the data down to only about 1 GB per second of data that will actually be stored.
-
Feedback loop processing
- Feedback loop processing refers to the analysis of the data to produce actionable results.
- While stream processing could be thought of as focused on inputs, feedback loop processing can be thought of as focused on outputs.
- The process of capturing the data, processing it into usable information, and then acting on that information is a feedback loop.
- In order for feedback loop processing to provide immediate results, it must be capable of analyzing large amounts of data within just a few seconds so that the results of the analysis can become a part of the product delivered to the user in real time.
-
The figure below shows a feedback loop for providing recommendations for book
purchases.
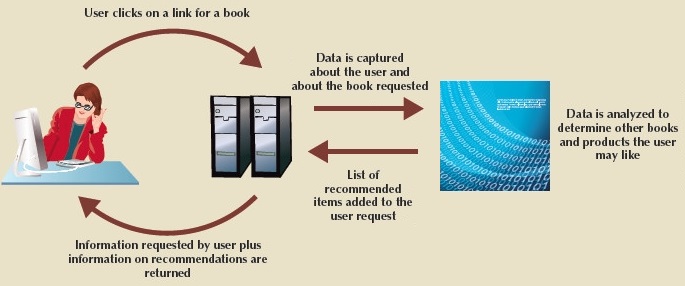
- Not all feedback loops are used for inclusion of results within immediate data products; feedback loop processing is also used to help organizations sift through terabytes and petabytes of data to inform decision makers to help them make faster strategic and tactical decisions, and it is a key component in data analytics.
Variety
Variety refers to the vast array of formats and structures in which the data may be captured.
Data can be considered to be structured, unstructured, or semistructured.
- Structured data is data that has been organized to fit a predefined data model.
- Unstructured data is data that is not organized to fit into a predefined data model.
- Semistructured data combines elements of both – some parts of the data fit a predefined model while other parts do not.
Although much of the transactional data that organizations use works well in a structured environment, most of the data in the world is semistructured or unstructured.
- Unstructured data includes maps, satellite images, emails, texts, tweets, videos, transcripts, and a whole host of other data forms.
Big Data requires that the data be captured in whatever format it naturally exists, without any attempt to impose a data model or structure to the data.
Veracity
Veracity is the authenticity and credibility of the data.
- Veracity helps to filter through what is important and what is not, and in the end, it generates a deeper understanding of data and how to contextualize it in order to take action.
- Removing things like bias, abnormalities or inconsistencies, duplication, and volatility are just a few aspects that factor into improving the accuracy of big data.
- The second side of data veracity entails ensuring the processing method of the actual data makes sense based on business needs and the output is pertinent to objectives.
Value
Value refers to the ability to turn data into value.
- Every decision made by a business should be data-driven.
- Adapting data to suit business needs will enable the business to unlock the hidden potential within the information that has been collected.
- All the volumes of fast-moving data of different variety and veracity have to be turned into value.
- This is why value is the one V of big data that matters the most.
But wait! There's more!
Big Data: The 6 Vs You Need to Look at for Important Insights
The 42 V’s of Big Data and Data Science
The 51 V's Of Big Data: Survey, Technologies, Characteristics, Opportunities, Issues and Challenges
Section 4: Tools
Emerging Big Data technologies allow organizations to process massive data stores of multiple formats in cost-effective ways.
Some of the most frequently used Big Data technologies are Hadoop, MapReduce, and NoSQL databases.
-
Hadoop is a Java based, open source, high speed, fault-tolerant distributed
storage and computational framework that allows for the
distributed processing of large data sets across clusters
of computers using simple programming models, and is designed
to scale up from single servers
to thousands of machines, each offering local computation and storage.
- Hadoop uses low-cost hardware to create clusters of thousands of computer nodes to store and process data.
- Hadoop originated from Google’s work on distributed file systems and parallel processing and is currently supported by the Apache Software Foundation.
- Hadoop has several modules, but the two main components are Hadoop Distributed File System (HDFS) and MapReduce.
- The figure below shows an example of the Hadoop ecosystem.
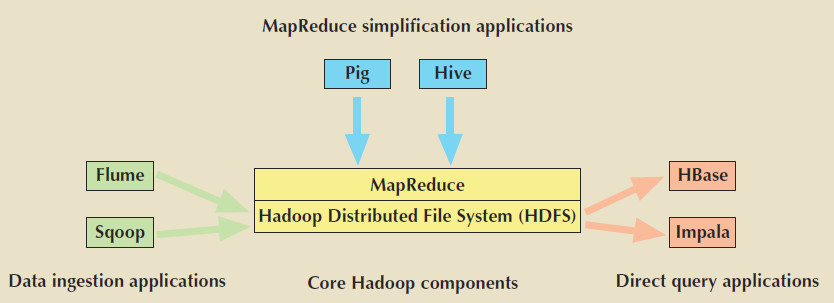
-
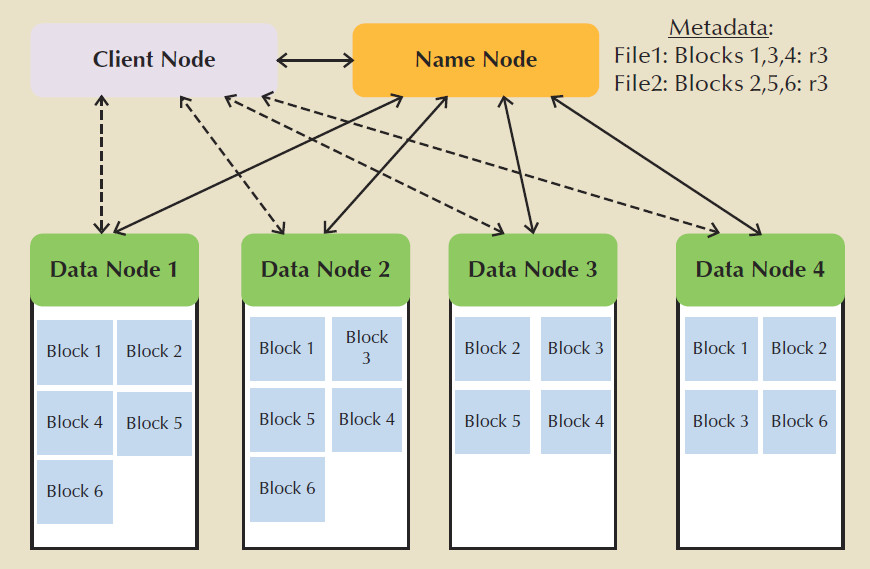
Hadoop Distributed File System (HDFS), shown in the figure below, is a
highly distributed, fault-tolerant file storage system designed to manage
large amounts of data at high speeds.
- In order to achieve high throughput, HDFS uses the write-once, read-many model, meaning that once the data is written, it cannot be modified.
-
HDFS uses three types of nodes:
- a name node that stores all the metadata about the file system
- a data node that stores fixed-size data blocks (that could be replicated to other data nodes)
- a client node that acts as the interface between the user application and the HDFS
-
MapReduce is an open source application programming interface (API)
that provides fast data analytics services.
- MapReduce distributes the processing of the data among thousands of nodes in parallel.
- MapReduce works with structured and nonstructured data.
-
The MapReduce framework provides two main functions, Map and Reduce.
- In general terms, the Map function takes a set of data and converts it into another set of data in which individual elements are broken down into tuples (key/value pairs).
- In the Reduce task, those data tuples output from the Map are combined into a smaller set of tuples, making it possible to analyze vast amounts of data in parallel across multiple clusters. The Reduce function then collects all the output results generated from the nodes and integrates them into a single result set.
-
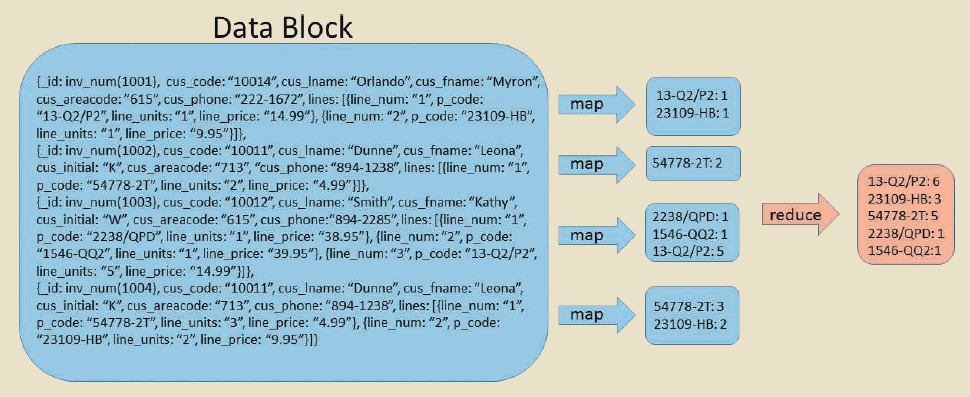
In the figure below, map functions parse each invoice
to find data about the products sold on that invoice.
- The result of the map function is a new list of key-value pairs in which the product code is the key and the line units are the value.
- The reduce function then takes that list of key-value pairs and combines them by summing the values associated with each key (product code) to produce the summary result.
- NoSQL is a large-scale distributed database system that stores structured and unstructured data in efficient ways.
Hadoop technologies provide a framework for Big Data analytics in which data (structured or unstructured) is distributed, replicated, and processed in parallel using a network of low-cost commodity hardware.
- Hadoop introduced new ways to store and manage data and Hadoop-related technologies gave rise to a new generation of database systems.
NoSQL databases provide distributed, fault-tolerant databases for processing nonstructured data.
Section 5: Summary
Big Data represents a new wave in data management challenges, but it does not mean that relational database technology is going away.
- Structured data that depends on ACID transactions will always be critical to business operations.
- Relational databases are still the best way for storing and managing this type of data.
What has changed is that now, for the first time in decades, relational databases are not necessarily the best way for storing and managing all of an organization's data.
- Since the rise of the relational model, the decision for data managers when faced with new storage requirements was not whether to use a relational database, but rather which relational DBMS to use.
- Now, the decision of whether to use a relational database at all is a real question.
- This has led to polyglot persistence – the coexistence of a variety of data storage and management technologies within an organization's infrastructure.