





Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| The student will be introduced to some of the theory behind the development of database engines, and will understand the complexity and challenges of developing multiuser databases. | The student will become familiar with the concept of concurrent transactions in a multiuser database. |
| The student will be able to explain the need for concurrency control stemming from the fact that the simultaneous execution of transactions over a shared database can lead to several data-integrity and consistency problems including lost updates, uncommitted data, and inconsistent retrievals. | |
| The student will learn what situations can result in a conflict between two database transactions. | |
| The student will learn that a multiuser database relies on a scheduler to establish the order in which the operations within concurrent transactions are executed. | |
| The student will learn that a multiuser database incorporates a lock manager. | |
| The student will learn about locks, lock granularity, locking methods, lock types, and time stamps, as well as that a multiuser database incorporates a lock manager to deal with locking conflicts, or deadlocks. | |
| The student will learn that there are some databases that are primarily read access, and therefore are unlikely to have database operations that conflict. | |
| The student will be introduced to database recovery management. |
Section 1: Overview
Concurrency control refers to the coordination of simultaneous execution of transactions in a multiprocessing database system
Objective: to ensure the serializability of transactions in a multiuser database environment.
Simultaneous execution of transactions over a shared database can lead to several data-integrity and consistency problems:
- Lost updates
- Uncommitted data
- Inconsistent retrievals
Section 2: Lost Updates
Lost updates occur when the results of one update are overwritten by another.
example:
- The quantity on hand (PROD_QOH) for a particular product is 35.
- Two concurrent transactions T1 and T2 update the PROD_QOH value for some item in the INVENTORY table at about the same time.
-
The transactions are

-
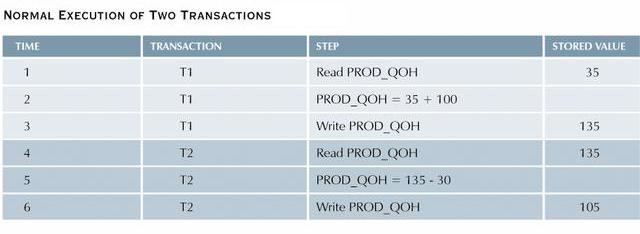
The following table shows the serial execution of these
transactions under normal circumstances, yielding the correct
answer, PROD_QOH = 105.
-
Suppose, however, that a transaction is able to read a product's
PROD_QOH value from a table before a previous transaction, which uses the
same product, has been committed. The following table shows an
operation sequence that results in a lost update:
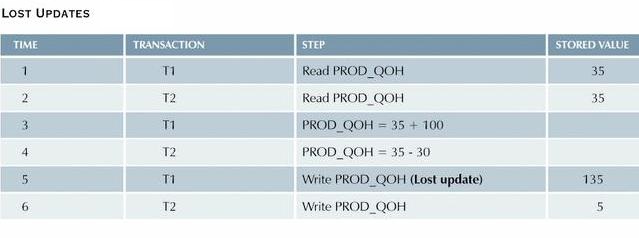
Note that the first transaction has not been committed when the second begins.
- Therefore, T2 still operates on the value 35, and its subtraction yields 5 in memory.
- In the meantime, T1 writes the value 135 to disk, but it is promptly overwritten by T2.
- Thus, the addition of 100 units is lost during the process.
Section 3: Uncommitted Data
Data are not committed when two transactions T1 and T2 are executed concurrently and the first transaction T1 is rolled back after the second transaction T2 has already accessed the uncommitted data.
- This violates the isolation property of transactions.
example:
- As before, the quantity on hand (PROD_QOH) for a particular product is 35.
- Two concurrent transactions T1 and T2 update the PROD_QOH value for the same item in the PRODUCT table at about the same time.
- However, this time the T1 transaction is rolled back to eliminate the addition of the 100 units.
- Since T2 subtracts 30 from the original 35 units, the correct answer should be 5.
-
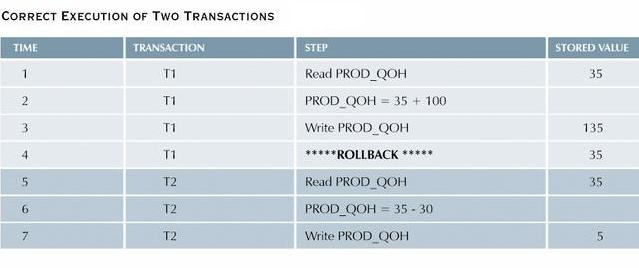
The transactions are

- The following table shows how, under normal
circumstances, the serial execution of these transactions yields the
correct answer.
-
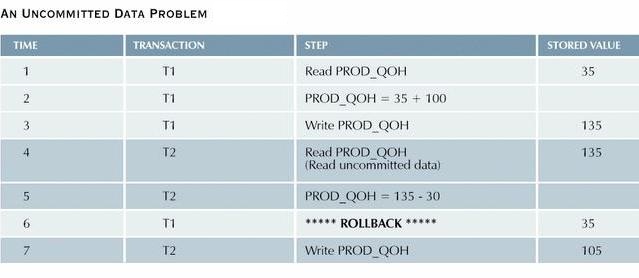
The next table shows how the uncommitted data problem can arise
when the ROLLBACK is completed after T2 has begun.
Section 4: Inconsistent Retrievals
Inconsistent retrievals occur when a transaction calculates some summary, or aggregate, functions over a set of data while other transactions are updating the data.
- The problem stems from the fact that the transaction may read some data before they are changed, and other data after they are changed, thereby yielding inconsistent results.
example:
-
Assume the following conditions:

-
The following table shows the transactions.

-
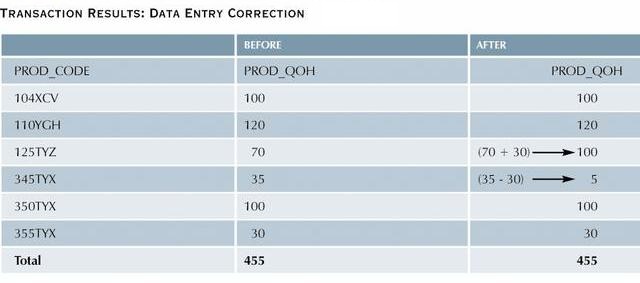
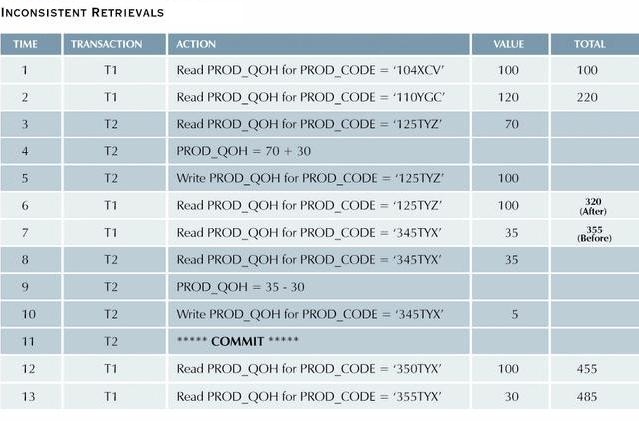
While T1 calculates the total PROD_QOH for all items, T2 represents
the correction of a typing error: the user added 30 units to
product '345TYX' instead of '125TYZ'. To correct the problem, 30
units are subtracted from '345TYX' and added to '125TYZ'.
-
However, inconsistent retrievals are possible if T1 read '125TYZ'
after it was corrected, but it read '345TYX' before the 30 units
were subtracted, so the total is 30 units too high.
Section 5: The Scheduler
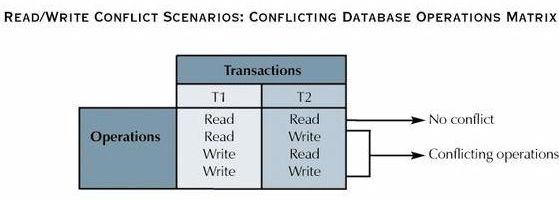
- As long as two transactions access unrelated data, there is no conflict, and the order of execution is irrelevant to the final outcome.
- If the transactions operate on related data, conflict is possible among the transaction components, and the selection of one operational order over another may have undesirable consequences.
- A DBMS includes a scheduler to establish the order in which the operations within concurrent transactions are executed.
-
Scheduling algorithms are based on the fact that two database
operations conflict only when they access the same data and at
least one of them is a WRITE operation.
- The scheduler bases its scheduling decisions on concurrency control algorithms, such as locking and time stamping methods.
Section 6: Locking Methods
A lock guarantees exclusive use of a data item to a current transaction.
example: Transaction T1 will be unable to access a data item that is currently being used by (and is therefore locked by) T2.
A transaction acquires a lock prior to data access; the lock is released when the transaction is completed.
Lock manager – initiates and enforces locking procedures; built in to most multiuser DBMSes.
Lock Granularity – refers to the level or scope of the lock
-
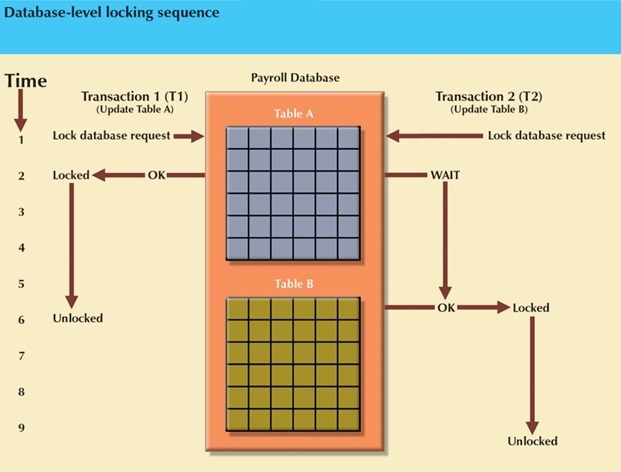
Database level:
- Entire database is locked.
- While transaction T1 is using the database, T2 cannot access any tables in the database.
- Database level is suitable for batch processes, but unsuitable for on-line multiuser database systems.
-
In the following figure, note that transactions T1 and T2 cannot access the same database
concurrently, even if they use different tables!
-
Table level:
- Entire table is locked.
- While transaction T1 is using the table, T2 cannot access any row in the table.
- If a transaction requires access to several tables, each of those tables may be locked.
- Two transactions can access the same database as long as different tables are used.
-
Because the users of multiuser database systems often require access to different parts of the same
table, table-level locks are not widely used.
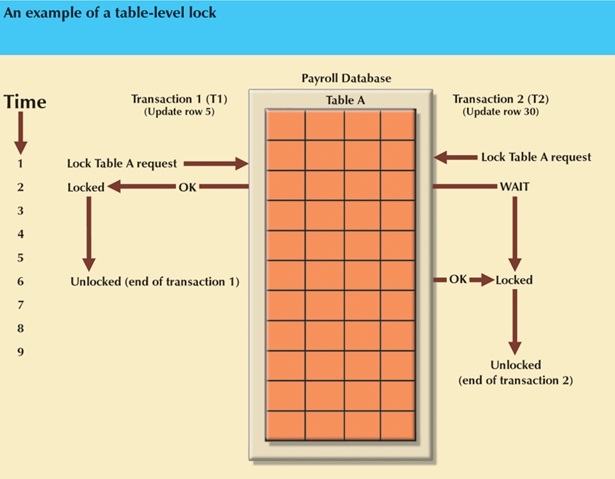
-
Page level:
- Entire disk-page is locked.
- A disk-page or page is the equivalent of disk-block, which is a directly addressable section of a disk. A page has a set size, such as 4K, 8K, 16K, etc. A table may span several pages, and a page may contain several rows of one or more tables.
- Page-level locks are the most widely-used locking approach.
- Concurrent transactions can access different rows of the same table, as long as the rows are located on different pages.
-
The following figure shows that T1 and T2 can access the same table as long as they have
locked different pages. If T2 requires the use of a row located on a page that is locked
by T1, T2 must wait until the page is unlocked by T1.
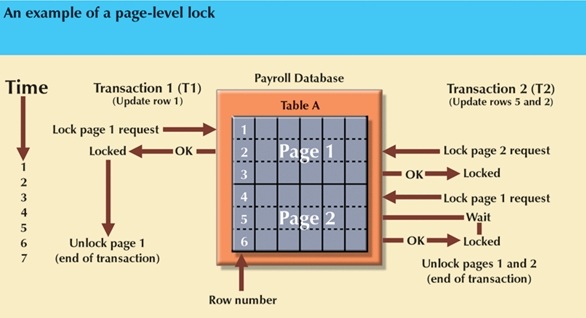
-
Row level:
- Single row is locked so less restrictive than previous methods.
- Concurrent transactions can access different rows of the same table, even if the rows are located on the same page.
- Improves the availability of data, but requires vast overhead, because a lock is required for each row in each table of the database.
-
MySQL 8.0 uses row-level locking for InnoDB tables, and table-level locking for MyISAM, MEMORY,
and MERGE tables. [link]
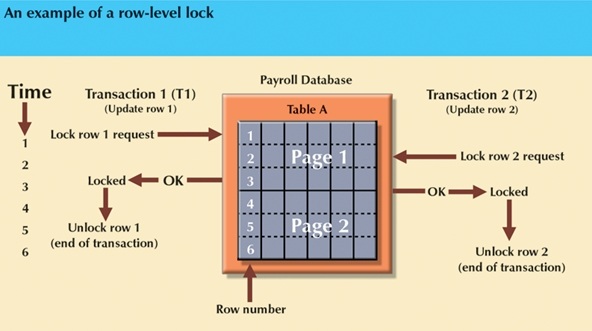
-
Field level:
- Single field is locked.
- Allows concurrent transactions to access the same row, as long as they require the use of different fields (attributes) within the row.
- Most flexible, most OVERHEAD!
Section 7: Lock Types
Regardless of the object (database, table, page, row, field) being locked, a DBMS may use different locking techniques, such as binary and shared/exclusive.
Binary locks:
- Two states: locked (1) or unlocked (0).
- If an object is locked, no other transaction can use it.
- If an object is unlocked, any transaction can lock it for its use.
- A transaction must unlock an object after its termination.
- Every database operation requires that the object be locked, so every transaction requires a lock and unlock operation for each data item that is accessed. This is handled by the DBMS, not the user.
- While binary locks can eliminate lost updates, etc., they are considered too restrictive to yield optimal concurrency conditions. For example, If two transactions want to read the same database object, the DBMS will not allow this to happen, even though neither transaction updates the database. (If neither updates, then no concurrency problem can occur, since conflicts can occur only when two transactions execute concurrently and at least one of them updates the database.)
-
The binary lock is shown in the table below to eliminate the lost updates problem discussed back in Section 2.
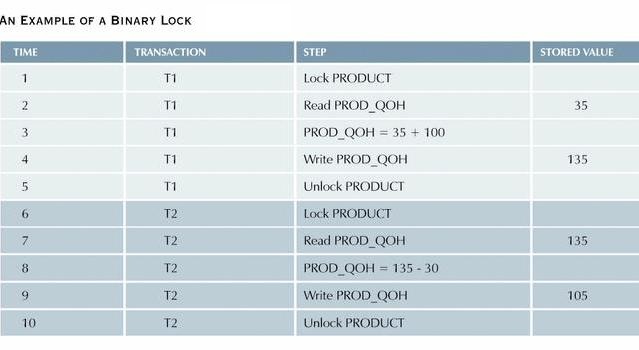
Shared/Exclusive locks:
- With a shared/exclusive locking system, a lock can have three states: unlocked, shared (READ) lock, and exclusive (WRITE) lock.
- A shared lock exists when concurrent transactions are granted READ access on the basis of a common lock. No conflict is possible when the concurrent transactions are read only.
- Shared locks allow several READ transactions to read the same data item.
- A shared lock is issued when a transaction wants to read data from an object and no exclusive locks are held on that object.
- An exclusive lock exists when access is reserved for the transaction that locked the object. The exclusive lock is necessary when two operations access the same object and at least one of them performs a WRITE operation.
- An exclusive lock is issued when a transaction wants to write (or update) an object and no other locks are currently held on that object by any other transaction.
-
The shared/exclusive lock schema increases the lock manager's overhead for several reasons:
- The type of lock held must be known before a lock can be granted.
- Three lock operations can exist: READ_LOCK (to check type of lock), WRITE_LOCK (to issue the lock), and UNLOCK (to release the lock).
- The schema allows a lock upgrade (from shared to exclusive) and a lock downgrade (from exclusive to shared).
-
While locks solve many problems, their use may lead to two major problems:
- The resulting transaction schedule may not be serializable (see properties).
- The schedule may create deadlocks (two transactions waiting for each other to unlock data).
- The first problem is solvable through the use of two-phase locking, and the second can be eliminated through the use of deadlock detection and prevention.
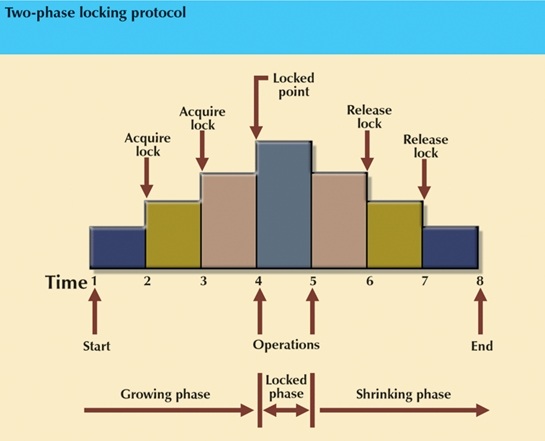
Section 8: Two-Phase Locking
Two-phase locking defines how locks are acquired and relinquished.
Two-phase locking guarantees serializability, but does not prevent deadlocks.
The two phases are:
-
Growing phase:
- In this phase a transaction acquires all the required locks without unlocking any data. Once all locks are acquired, the transaction is in its locked point.
-
Shrinking phase:
- In this phase a transaction releases all locks and cannot obtain a new lock.
Two-phase locking is subject to the following rules:
- Two transactions cannot have conflicting locks.
- No unlock operation can precede a lock operation in the same transaction.
- No data are affected until all locks are obtained, i.e., the transaction is in its locked point.
Section 9: Deadlocks
Deadlocks exist when two transactions T1 and T2 exist in the following mode:

If T1 has not unlocked item Y, T2 cannot begin; and if T2 has not unlocked item X, T1 cannot begin. Consequently, T1 and T2 wait indefinitely, each waiting for the other to unlock the required data item.
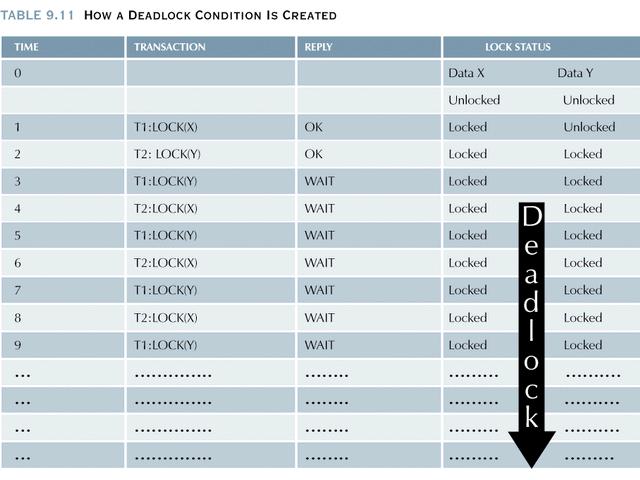
In a real-world DBMS several transactions may be executed concurrently, thereby increasing the probability of generating deadlocks.
Deadlocks are possible only if one of the transactions wants to obtain an exclusive lock on a data item.
Three basic techniques exist to control deadlocks:
-
Deadlock prevention:
- A transaction requesting a new lock is aborted if there is the possibility that a deadlock may occur.
- If the transaction is aborted, all the changes made by the transaction are rolled back, and all locks obtained by the transaction are released.
- The transaction is then rescheduled for execution.
- Deadlock prevention works because it avoids the conditions that lead to deadlocks.
-
Deadlock detection:
- The DBMS periodically tests the database for deadlocks.
- If one is found, one of the transactions is aborted (rolled back and restarted), and the other transaction continues.
-
Deadlock avoidance:
- The transaction must obtain all the locks it needs before it can be executed.
- This technique avoids rollback of conflicting transactions by requiring that locks be obtained in succession.
- However, the serial lock assignment required in deadlock avoidance increases response times.
The database environment dictates the best deadlock control method:

Section 10: Time Stamping Methods
Each transaction is assigned a global unique time stamp, which provides an explicit order in which transactions were submitted to the DBMS.
Time stamps must possess two properties:
- uniqueness – no equal time stamps can exist
- monotonicity – time stamp values always increase
All operations within the same transaction must have the same time stamp.
The DBMS executes conflicting operations in time stamp order, thereby ensuring serializability of the transactions.
If two transactions conflict, one is stopped, rescheduled, and assigned a new time stamp value.
Time stamping increases overhead because each value stored in the database requires two time stamp fields: one for the last time the field was read and one for the last update.
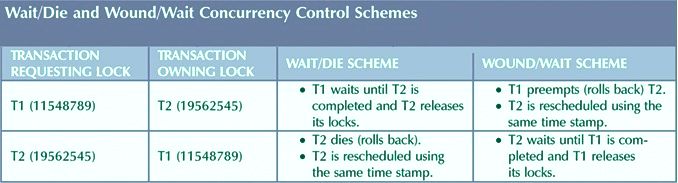
Wait/Die and Wound/Wait Schemes
- The following two schemes are used to decide which transaction is rolled back and which continues executing.
-
In the following table, T1 has an earlier time stamp and is therefore older.
-
Wait/die
- If the transaction requesting the lock is older, it will wait until the younger transaction is completed and the locks released.
- If the transaction requesting the lock is younger, it will die (roll back) and be rescheduled using the same time stamp.
-
Wound/wait
- If the transaction requesting the lock is older, it will preempt (wound) the younger transaction (by rolling it back), and the younger will be rescheduled using the same time stamp.
- If the transaction requesting the lock is younger, it will wait until the other transaction is completed and the locks are released.
-
Wait/die
-
To avoid deadlocks in a multilock scenario, each lock request has an associated time-out value.
- If a lock is not granted before the time-out expires, the transaction is rolled back.
Section 11: Optimistic Methods
Optimistic methods are based on the assumption that the majority of database operations do not conflict, hence the optimistic approach does not require locking or time stamping. [link]
{kind=link}
The optimistic method allows a transaction to execute without restrictions until it is committed.
Each transaction passes through two or three phases:
-
Read phase:
- The transaction reads the database, performs the necessary computations, and makes updates to a private copy of the database values.
- All update operations of the transaction are recorded in a temporary update file, which cannot be accessed by the remaining transactions.
-
Validation phase:
- The transaction is validated to assure that the changes made will not affect the integrity and consistency of the database.
- If the validation test is positive, the transaction moves to the write phase, otherwise the transaction is restarted and the changes are discarded.
-
Write phase:
- The changes are permanently applied to the database.
This approach is acceptable for database systems that perform mostly reads or queries, and require very few update transactions.
Section 12: Database Recovery Management
Restores database to previous consistent state.
Recovery techniques are based on the atomicity property:
- All portions of the transaction are treated as a single logical unit of work
- All operations are applied and completed to produce a consistent database
If the transaction operation cannot be completed:
- The transaction is aborted
- Changes to the database are rolled back
There are several important concepts that affect the recovery process, including:
- Write-ahead-log protocol: ensures transaction logs are written to permanent storage before data is updated so that in case of failure, the database can later be recovered to a consistent state using the data in the transaction log.
- Redundant transaction logs: ensure physical disk failure will not impair the DBMS's ability to recover data.
- Buffers: temporary storage areas in primary memory (more).
- Checkpoints: operations in which the DBMS writes all its updated buffers to disk.
Deferred-write technique (also called a deferred update)
-
With this technique transactions do not immediately update the physical database,
but rather only update the transaction log.
- The database is physically updated only after the transaction reaches its commit point, using information from the transaction log.
- If the transaction aborts before it reaches its commit point, no changes need to be made to the database because the database was never updated.
-
Recovery process for all started and committed transactions (before the failure)
follows these steps:
- Identify the last checkpoint in the transaction log. This is the last time transaction data was physically saved to disk.
- For a transaction that started and was committed before the last checkpoint, nothing needs to be done because the data is already saved.
- For a transaction that performed a commit operation after the last checkpoint, the DBMS uses the transaction log records to redo the transaction and update the database, using the "after" values in the transaction log. The changes are made in ascending order, from oldest to newest.
- For any transaction that had a ROLLBACK operation after the last checkpoint or that was left active (with neither a COMMIT nor a ROLLBACK) before the failure occurred, nothing needs to be done because the database was never updated.
Write-through technique (also called an immediate update)
-
The database is immediately updated by transaction operations during
the transaction's execution, even before the transaction reaches its
commit point.
- If the transaction aborts before it reaches its commit point, a ROLLBACK operation needs to be done to restore the database to a consistent state.
- In that case, the ROLLBACK will use the transaction log "before" values.
-
Recovery process:
- Identify the last checkpoint in the transaction log. This is the last time transaction data was physically saved to disk.
- For a transaction that started and was committed before the last checkpoint, nothing needs to be done because the data is already saved.
- If the transaction committed after the last checkpoint, the DBMS redoes the transaction using "after" values of the transaction log. Changes are applied in ascending order, from oldest to newest.
- For any transaction that had a ROLLBACK operation after the last checkpoint or that was left active (with neither a COMMIT nor a ROLLBACK) before the failure occurred, the DBMS uses the transaction log records to ROLLBACK or undo the operations, using the “before” values in the transaction log. Changes are applied in reverse order, from newest to oldest.
See the example using Table 10.15.