





Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| The student will be able to list and explain basic data warehouse concepts. | The student will be able to explain the purpose of a data warehouse and how it differs from a database. |
| The student will be able to explain the difference between operational and analytical data. | |
| The student will be able to list and explain the components that make up a data warehouse. | |
| The student will be able to explain related concepts like data lakes and data marts. | |
| The student will be able to list and explain the steps involved in the development of a data warehouse. |
Section 1: Overview
Data warehouses are central repositories of integrated data from one or more disparate sources, and they store current and historical data in one single place that are used for creating analytical reports for workers throughout the enterprise.
- A data warehouse exists as a layer on top of another database or databases, and takes the data from all these databases and creates a layer optimized for and dedicated to analytics.
-
Data warehouses and databases are both relational data systems, but were built to serve different purposes.
- A data warehouse is built to store large quantities of historical data and enable fast, complex queries across all the data, typically using Online Analytical Processing (OLAP).
- A database is built to store current transactions and enable fast access to specific transactions for ongoing business processes, known as Online Transaction Processing (OLTP).
- A data warehouse is a system used for reporting and data analysis, and is considered a core component of business intelligence.
Here is a brief Introduction to Data Warehouses
Here is a very general Explanation of Data Warehouses
This is a more thorough discussion of What is a Data Warehouse?
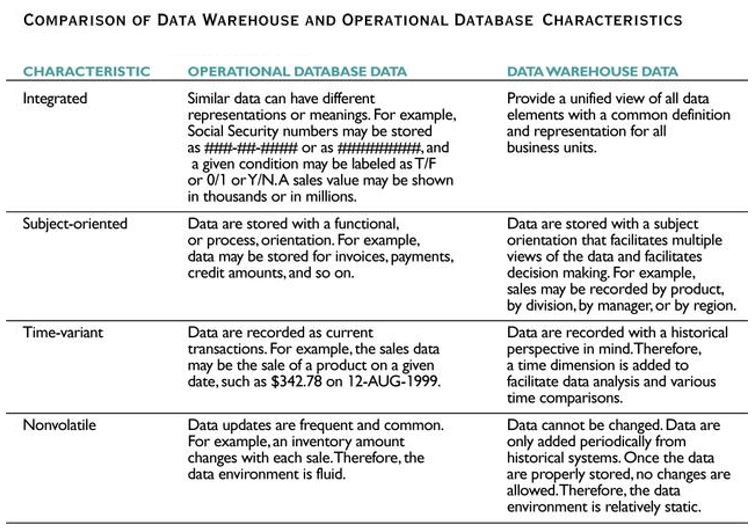
The Data Warehouse is a structured repository of integrated, subject-oriented, enterprise-wide, historical, time-variant data that provides support for decision making.
-
Structured repository
- The data warehouse is a database containing analytically useful information.
- Any database is a structured repository with its structure represented in its metadata.
- The data warehouse, being a database, is a structured repository. In other words, the data warehouse is not a disorganized random mass of data.
-
Integrated
- The data warehouse integrates the analytically useful data from the various operational databases (and possibly other sources).
- Integration refers to this process of bringing the data from multiple data sources into a singular data warehouse.
- In the process of bringing the data from operational databases into the data warehouse, no data is actually removed from the operational sources. Instead, the analytically useful data from various operational databases is copied and brought into the data warehouse.
-
Subject-oriented
-
The term subject-oriented refers to the fundamental difference in the purpose of an operational database system and a data warehouse.
- An operational database system is developed in order to support specific business operations.
- A data warehouse is developed to analyze specific business subject areas.
- Data warehouse data is arranged and optimized to provide answers to questions coming from diverse functional areas within a company.
-
The term subject-oriented refers to the fundamental difference in the purpose of an operational database system and a data warehouse.
-
Enterprise-wide
- The term enterprise-wide refers to the fact that the data warehouse provides an organization-wide view of the analytically useful information it contains.
- For example, if one of the subjects of the data warehouse is cost, then all of the analytically useful data regarding cost within the operational data sources in the entire organization will be brought into the data warehouse.
-
Historical
- The term historical refers to the larger time horizon in the data warehouse than in the operational databases.
- For example, many traditional operational databases have a time horizon of 60 to 90 days, where it is quite common for data warehouses to contain multiple years' worth of data.
-
Time variant
-
The term time variant refers to the fact that a data warehouse contains slices or snapshots of data from different periods of time across its time horizon.
- With the data slices, the user can create reports for various periods of time within the time horizon.
- For example, if the subject of analysis is cost and the time horizon is a number of years, we can analyze and compare the cost for the first quarter from a year ago versus the cost for the first quarter from two years ago.
-
The term time variant refers to the fact that a data warehouse contains slices or snapshots of data from different periods of time across its time horizon.
Retrieval of analytical information
-
A data warehouse is developed for the retrieval of analytical information, and it is not meant for direct data entry by users.
- The only functionality available to the users of the data warehouse is retrieval.
- The data in the data warehouse is not subject to modifications, insertions, or deletions by users.
-
The data in the data warehouse is not subject to changes, and is referred to as non-volatile, static, or read-only.
- New data in the data warehouse is periodically loaded from the operational data sources and appended to the existing data, in an automatic fashion.
- The data that eventually gets older than the required time horizon is automatically purged from the data warehouse (and possibly archived and/or summarized).
Detailed and/or summarized data
-
A data warehouse, depending on its purpose, may include detailed data, or summary data, or both.
-
The detailed data is also called atomic data, or transaction-level data.
- For example, a table in which each ATM transaction is recorded as a separate record contains detailed data (i.e., atomic or transaction-level data).
-
A table in which a record represents calculations based on multiple instances of transaction-level data contains summarized data at a coarser level of detail.
- For example, a summarized data record could represent the total amount of money withdrawn in one month from one account via an ATM.
-
The detailed data is also called atomic data, or transaction-level data.
-
A data warehouse that contains data at the finest level of detail is the most powerful, because all summaries can be calculated from it and stored if they are to be repeatedly used.
- In some cases, storing all of the analytical data at the transaction level of detail for large time horizons is cost prohibitive.
- In some other cases, organizations may decide that for some subjects of analysis, summarizations are adequate and transaction-level detail data is not necessary.
- Finally, when the company is not able or does not want to have all of its required analytical information at the finest level of detail, the data for some (or all) of the subjects of analysis in the data warehouse is kept only at a certain level of summarization.
Section 2: Justification
What Is A Data Warehouse And Why Do We Build Them?
A typical organization maintains and utilizes a number of operational data sources.
- The operational data sources include the databases and other data repositories that are used to support the organization’s day-to-day operations.
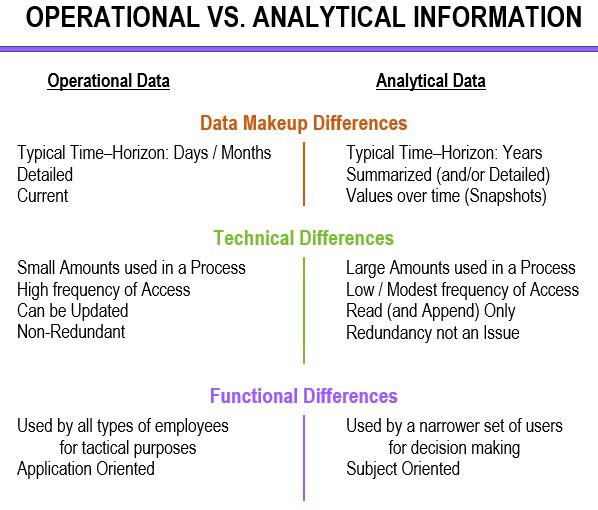
A data warehouse is created within an organization as a separate data store whose primary purpose is data analysis.
Often, the same fact can have both an operational and an analytical purpose.
- For example, data describing that customer X bought product Y in store Z can be stored in an operational database for business-process support purposes, such as inventory monitoring or financial transaction record keeping.
- That same fact can also be stored in a data warehouse where, combined with a vast number of similar facts accumulated over a period of time, it serves to reveal important trends, such as sale patterns or customer behavior.
There are two main reasons for the creation of a data warehouse as a separate analytical database.
- The performance of operational day-to-day tasks involving data use can be severely diminished if such tasks have to compete for computing resources with analytical queries.
-
It is often impossible to structure a database that can be used in an efficient manner for both operational and analytical purposes.
- Operational information (or transactional information) is the information collected and used in support of day-to-day operational needs in businesses and other organizations.
-
Analytical information is the information that is collected and used in support of analytical tasks.
- Analytical information is based on operational (transactional) information.
Section 3: Data Warehouse Components
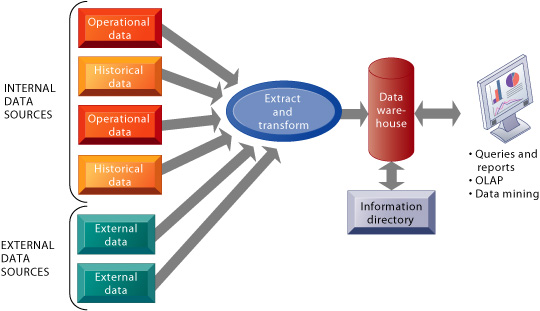
Data warehouse components
- Source systems
- Extraction-transformation-load (ETL) infrastructure
- Data warehouse
- Front-end applications
Source Systems
- In the context of data warehousing, source systems are operational databases and other operational data repositories (in other words, any sets of data used for operational purposes) that provide analytically useful information for the data warehouse’s subjects of analysis.
-
Every operational data store that is used as a source system for the data warehouse has two purposes:
- The original operational purpose.
- As a source system for the data warehouse.
- Source systems can include external data sources, such as market research data, census data, stock market data, and weather data.
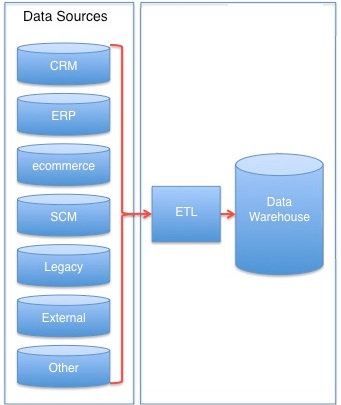
Extract - Transform - Load infrastructure
- The ETL infrastructure facilitates the retrieval of data from operational databases into the data warehouse.
- This process involves taking (extracting) data from a source system, converting (transforming) it into a format that can be analyzed, and storing (loading) it into a data warehouse.
-
ETL includes the following tasks:
-
Extracting analytically useful data from the operational data sources.
- The extract stage determines different data sources, the refresh rate (velocity) of each source, and the priorities (extract order) between them – all of which heavily impact time-to-insights.
-
Transforming such data so that it conforms to the structure of the subject-oriented target data warehouse model (while ensuring the quality of the transformed data).
- Transformations bring clarity and order to the initial data. For example,
- dates may be consolidated into specified time buckets.
- strings may be parsed to their business meanings.
- transactions may be modeled into events.
- location data may be translated to coordinates, zip codes, or cities/countries.
- measures may be summed up, averaged, rounded.
- useless data and errors may be set aside for later inspection.
-
The transform phase of ETL may require the development of a specialized ETL script to transform that data, but before the script can be run the data must be analyzed and cleaned to ensure that the ETL can execute without failure.
-
Data cleansing is the process of ensuring that data is correct, consistent, and usable by identifying any errors or corruptions in the data, correcting or deleting them, or manually processing them as needed to prevent the error from happening again.
- The inconsistencies detected or removed may have been originally caused by user entry errors, by corruption in transmission or storage, or by different data dictionary definitions of similar entities in different stores.
-
The actual process of data cleansing may involve removing typographical errors or validating and correcting values against a known list of entities.
- The validation may be strict (such as rejecting any address that does not have a valid postal code) or fuzzy (such as correcting records that partially match existing, known records).
- A common data cleansing practice is data enhancement, where data is made more complete by adding related information.
- Cleansing may involve removing irrelevant data, i.e., those that are not actually needed and don’t fit under the context of the problem we’re trying to solve, as well as duplicated data, or those data points that are repeated in a dataset.
- Cleansing may also require type conversions to ensure that numbers are stored as numerical data types, dates as a date objects or Unix timestamps, etc.
- In addition, syntax errors must be dealt with, including removing extraneous white space at the beginning or end of a string, padding strings with spaces or other characters to a certain width, putting data in a standardized format, and transforming data so that it fits within a specific scale.
- After cleansing, a data set should be consistent with other similar data sets in the system.
-
Data cleansing is the process of ensuring that data is correct, consistent, and usable by identifying any errors or corruptions in the data, correcting or deleting them, or manually processing them as needed to prevent the error from happening again.
-
Loading the transformed and quality assured data into the target data warehouse.
- In the last phase, much as in the first, targets and refresh rates are determined.
- Moreover, the load phase determines whether loading will be done by increments or if updating existing data and inserting new data is required for the new batches of data.
- Transformations bring clarity and order to the initial data. For example,
-
Extracting analytically useful data from the operational data sources.
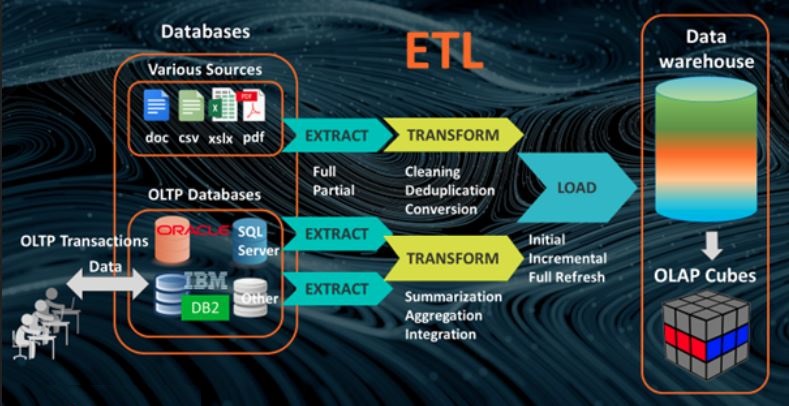
Data warehouse
- The data warehouse is sometimes referred to as the target system, to indicate the fact that it is a destination for the data from the source systems.
- A typical data warehouse periodically retrieves selected analytically useful data from the operational data sources.
Data warehouse front-end (BI) applications
- Used to provide access to the data warehouse for users who are engaging in indirect use.
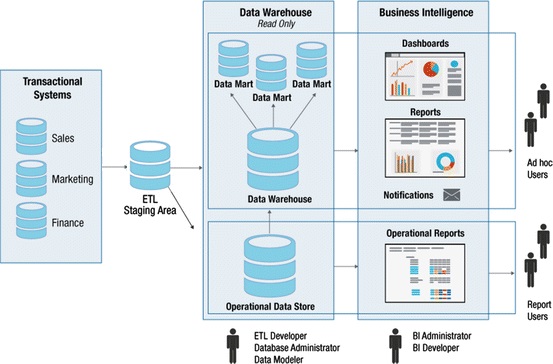
Section 4: Data Marts
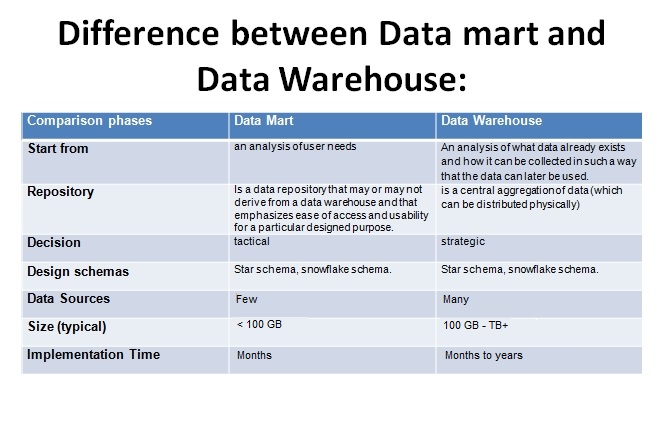
A data mart is a data store based on the same principles as a data warehouse, but with a more limited scope.
- A data mart is a subject-oriented database that is often a partitioned segment of an enterprise data warehouse.
- Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department.
- The subset of data held in a data mart typically aligns with a particular business unit like sales, finance, or marketing.
There are two major categories of data marts: independent data marts and dependent data marts.
-
An independent data mart is a stand-alone data mart, with its own source systems and ETL infrastructure.
- The difference between an independent data mart and a data warehouse is a single subject, fewer data sources, smaller size, shorter implementation, and a narrower focus.
-
A dependent data mart does not have its own source systems, abut rather gets its data from the data warehouse.
- Dependent data marts are simply a way to provide users with a subset of the data from the data warehouse, in cases when users or applications do not want, need, or are not allowed to have access to all the data in the entire data warehouse.
While we are muddying the analogy waters, let's see some other buzzwords that describe variations of a data warehouse.
- data lake – While a data warehouse is a repository for structured, filtered data, a data lake is a central storage repository that holds big data from many sources in a raw, granular format, storing structured, semi-structured, or unstructured data.
- data river – Supposedly a more accurate analogy than data lake.
- data reservoir – A data reservoir is (in theory) a data lake that has been partly filtered, secured, and made ready for consumption. Imagine a lake that’s been drained and filtered into a reservoir, creating a source of potable drinking water.
- data lakehouse – A data lakehouse combines the best elements of data lakes and data warehouses, made possible by a new system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low-cost storage used for data lakes.
- data swamp – A data swamp has little organization and little to no active management throughout the data life cycle and little to no contextual metadata and data governance, making them less useful and frustrating.
- data ocean – A data lake is often used for data specific to a certain part of the business. A data ocean, on the other hand, comprises unprocessed data from the entire scope of the business.
- data pond – Data ponds are subsets of data lakes that are separated for privacy (i.e., personally identifiable information), governance, technology, or costs.
- data droplet – Data droplets are the basic element, describing information and dimensions about the subject.
And then there is this outlier, which has no reference to water but is still related to data warehouses. They could have at least stayed with the theme by calling it a data ice cube!
- data cube – A data cube is a way of modeling analytical relational data from a data warehouse for rapid reporting and analytical querying.
- Data cubes arrange data into matrices of three or more dimensions, cross-referencing tables from single or multiple data sources to increase the detail associated with each data point.
- This transformation connects the data to a position in rows and columns of more than one table.
- Knowledge workers can rapidly and efficiently query data cubes to create data volumes to drill down into and discover the deepest insights possible.
Section 5: Steps in the Development of Data Warehouses
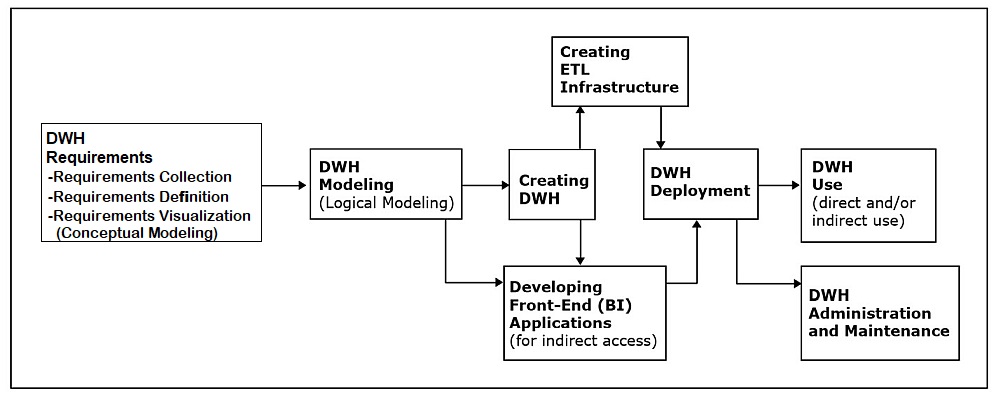
Requirements collection, definition, and visualization
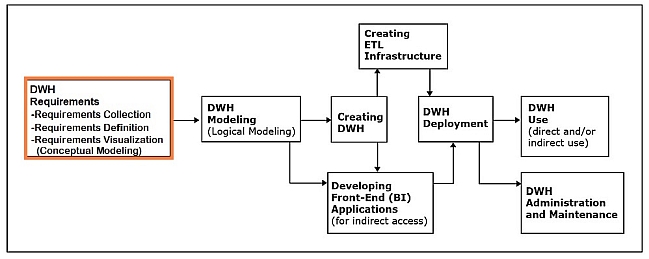
This phase results in the requirements specifying the desired capabilities and functionalities of the future data warehouse.
- The requirements are based on the analytical needs that can be met by the data in the internal data source systems and available external data sources.
- The requirements are collected through interviewing various stakeholders of the data warehouse.
-
In addition to interviews, additional methods for eliciting requirements from the stakeholders can be used.
- Additional methods for eliciting requirements include focus groups, questionnaires, surveys, and observations of existing analytical practices to determine what users really do with data and what data they actually use and need
- The collected requirements should be clearly defined and stated in a written document, and then visualized as a conceptual data model.
Requirements collection is the most critical step in the development of the data warehouse.
Data warehouse modeling (logical data warehouse modeling)
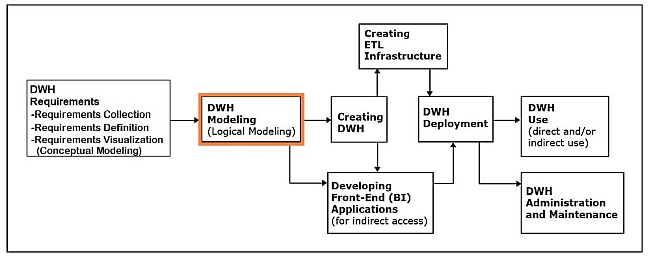
This phase involves creation of the data warehouse data model that is implementable by the DBMS software.
Creating the data warehouse
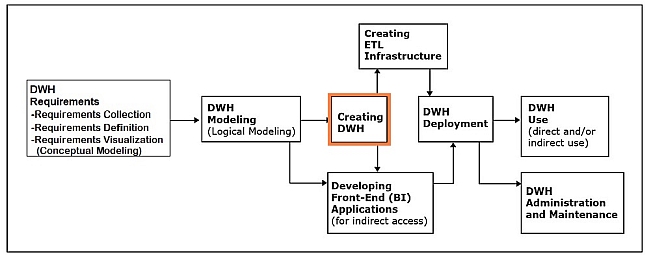
This phase involves using a DBMS to implement the data warehouse data model as an actual data warehouse.
-
Typically, data warehouses are implemented using a relational DBMS (RDBMS) software like Oracle or SQL Server.
- However, other relational DBMS packages, such as Teradata, that are specialized for processing large amounts of data typically found in data warehouses are also available for implementation of data warehouses.
Creating ETL infrastructure
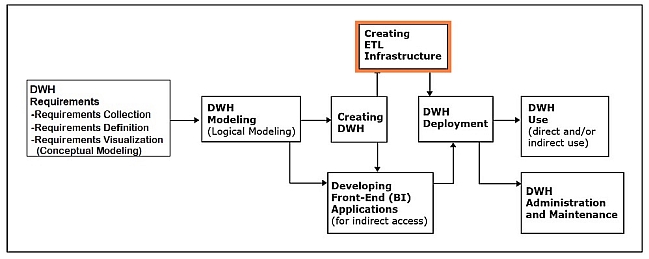
This phase involves creating necessary procedures and code for:
- Automatic extraction of relevant data from the operational data sources.
- Transformation of the extracted data, so that its quality is assured and its structure conforms to the structure of the modeled and implemented data warehouse.
- The seamless load of the transformed data into the data warehouse
Due to the amount of details that have to be considered, creating ETL infrastructure is often the most time- and resource-consuming part of the data warehouse development process.
ETL infrastructure has to account for and reconcile all of the differences in the metadata and the data between the operational sources and the target data warehouses.
- In many cases, organizations have multiple separate operational sources with overlapping information.
- In such cases, the process of creating the ETL infrastructure involves deciding how to bring in such information without creating misleading duplicates (i.e., how to bring in all the useful information while avoiding the uniqueness data quality problem).
Developing front-end (BI) applications
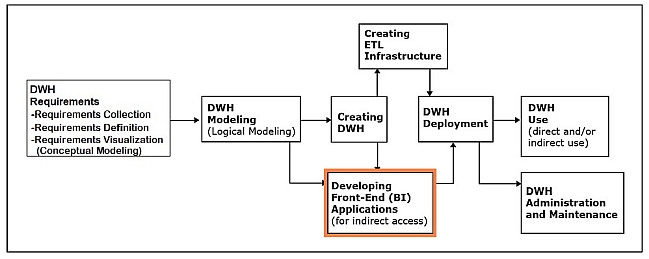
This phase involves designing and creating applications for indirect use by the end-users.
- Front-end applications are included in most data warehousing systems and are often referred to as business intelligence (BI) applications.
- Front-end applications contain interfaces (such as forms and reports) accessible via a navigation mechanism (such as a menu)
The design and creation of data warehouse front-end applications can take place in parallel with data warehouse creation.
- For example, the look and feel of the front-end applications, as well as the number and functionalities of particular components (e.g., forms and reports), can be determined before the data warehouse is implemented.
- This can be done based on the data warehouse model and the requirements specifying the capabilities and functionalities of the system needed by the end users.
- The actual creation of the front-end application involves connecting it to the implemented data warehouse, which can only be done once the data warehouse is implemented.
Data warehouse deployment
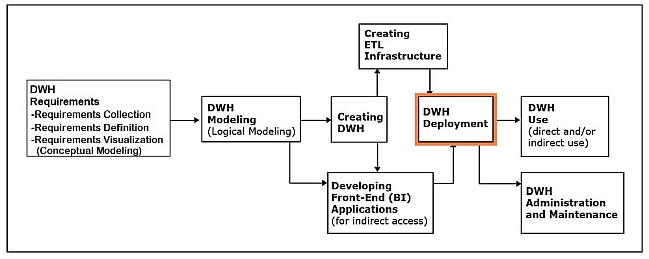
This phase involves releasing the data warehouse and its front-end (BI) applications for use by the end users
Typically, prior to this step, the initial load populating the created data warehouse with an initial set of data from the operational data sources via the ETL infrastructure is executed.
Data warehouse use
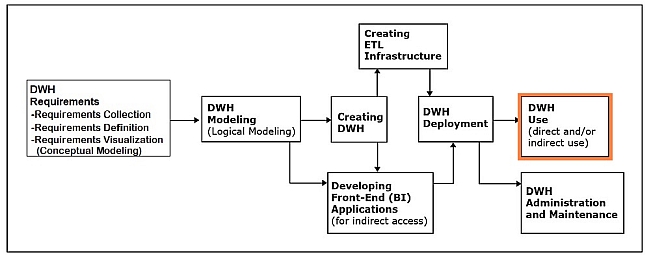
This phase involves the retrieval of the data in the data warehouse.
-
Indirect use
- Via the front-end (BI) applications
-
Direct use
- Via the DBMS
- Via the OLAP (BI) tools
Data warehouse administration and maintenance
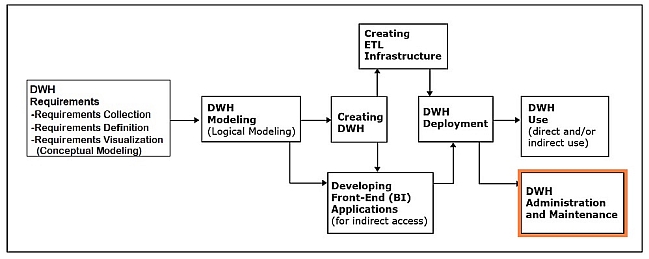
This phase involves performing activities that support the data warehouse end user, including dealing with technical issues, such as:
- Providing security for the information contained in the data warehouse.
- Ensuring sufficient hard-drive space for the data warehouse content.
- Implementing the backup and recovery procedures.