Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| The student will be able to recognize database anomalies and explain the significant disadvantages associated with the presence of such anomalies. | The student will be able to detect poor design features that can lead to insertion, deletion, and modification anomalies and how they degrade a database. |
| The student will be able to detect repeating groups and understand their deleterious effect on query execution. | |
| The student will be able to recognize partial dependencies and understand their harmful effect on query execution. | |
| The student will be able to recognize transitive dependencies and understand how they can degrade query execution. |
| The student will be able to apply the normalization approach to remove database anomalies to improve database functionality. | The student will be able to apply the process for eliminating repeating groups in order to convert each relation to First Normal Form. |
| The student will be able to apply the process for eliminating partial dependencies in order to convert each relation to Second Normal Form. | |
| The student will be able to apply the process for eliminating transitive dependencies in order to convert each relation to Third Normal Form. | |
| The student will be introduced to higher level normal forms like Boyce-Codd Normal Form, Fourth Normal Form, Fifth Normal Form, and Domain/Key Normal Form. |
Section 1: Overview
Easy explanation of Normalization
Definition:
- A process for converting complex data structures into simple stable data structures.
- A process during which unsatisfactory relation schemas are decomposed by breaking up their attributes into smaller relation schemas that possess desirable properties.
Objective:
- Normalization produces the controlled redundancy that allows database tables to be linked.
- One objective of normalization is to ensure that update anomalies do not occur.
Justification:
- Normal forms provide the database designer with a formal framework for analyzing relation schemas based on their keys and on the functional dependencies among their attributes.
- Normal forms provide the database designer with a series of tests that can be carried out on individual relation schemas so that the relational database can be normalized to any degree. When a test fails, the relation violating that test must be decomposed into relations that individually meet the normalization tests.
-
Inexperienced (or poor) database designers will sometimes attempt to develop a
database by mimicking a report:
Problems:- The intended primary key contains null values.
- There is redundant data, such as EMP_NAME, JOB_CLASS, and CHG_HOUR.
- The table entries are prone to data inconsistencies, such as the abbreviation for electrical engineer.
-
The redundancies lead to the following anomalies:
- update anomalies – any modification to JOB_CLASS may require many alterations.
- addition anomalies – to add a new project, at least one employee must be assigned to it.
- deletion anomalies – if the first employee assigned to a project, such as 103, quits and is deleted, additional project data is also lost.
Section 2: Anomalies
Definition:
- Certain collections of relations have better properties in an updating environment than do other collections of relations containing the same data.
- Relations may exhibit incorrect behavior when updates are performed. Such incorrect behaviors are referred to as anomalies.
Types:
There are three kinds of anomalies:
- insertion anomaly
- deletion anomaly
- modification (update) anomaly
Consider the following relational scheme and the corresponding relation:
STUDENT_COURSE (Bengal_ID, S_Name, Course#, Course_Title, Instr_Name, Instr_Office, Grade)

Insertion Anomaly
- Definition: Data insertion is not possible until an instance provides values for all attributes in a composite key.
- Scenario: Suppose we want to insert new course data into this relation. For example, we may want to insert INFO 4407, Database. We cannot insert this data until at least one student has registered for this course, since Bengal_ID is part of the composite key. Similar anomalies occur in attempting to insert new instructor data.
Deletion Anomaly
- Definition: The scheme is constructed such that the deletion of incidental data results in the deletion of important data.
- Scenario: Suppose only one student is enrolled in a course, such as Data Analytics. If the student drops that course, we want to delete that tuple from the database. Unfortunately, this will result in lost information about the title and instructor of the course.
Modification Anomaly
- Definition: When a value is duplicated in multiple tuples, changing that value requires that all tuples with that value be changed.
- Scenario: Suppose we want to change the course title for INFO 3380 from Networking to Net Admin. Since the title of this course appears in STUDENT_COURSE a number of times, the user will have to search through all the tuples in this relation and update the course title each time it occurs. This procedure will be inefficient and can result in inconsistencies if all occurrences are not correctly updated.
Section 3: Repeating Groups
Definition:
- Repeating groups occur when an attribute has a group of related data entries. If repeating groups are not eliminated, even basic relational algebra operators can fail to work correctly.
Suppose there is a relation called STUDENT with the following schema:
STUDENT (Bengal_ID, S_Name, S_Major, (S_Minor), S_Credits, S_Class)
Consider the following entries:

- Will the relational algebra command SELECT STUDENT WHERE MINOR = 'Computer Science' list the record for Murphy, or not?
- If a natural join is attempted with some other table using S_MINOR as the joining column, would this record be paired with only those having both Data Analytics and Computer Science as a minor, or with those having either Data Analytics or Computer Science?
Summary: Repeating groups result in unpredictable results from the relational algebra commands, and thus must be eliminated.
Not all anomalies can be avoided, but a good design greatly reduces them.
Solution: Split the relational scheme up using the normalization process to avoid anomalies.
STUDENT (Bengal_ID, S_Name, S_Major, S_Credits, S_Class)
STUDENT_MINOR (Bengal_ID,
S_Minor)
The normalization process simplifies relations by breaking them up into smaller relations.
To avoid anomalies, each relation should contain information about a single object.
Section 4: Normalization Details (Partiality and Transitivity)
Simpler relations can be derived by a series of mathematical steps known as normalization.
Normalization uses the notion of dependency. The idea is to only include things (attributes) that are related to, or dependent on, the primary key, i.e., group attributes that are functionally dependent.
RECALL: an attribute B of relation R is functionally dependent on attribute A if, at every instant of time, each A-value in R is associated with one and only one B-value.
Partial functional dependency occurs if a non-key attribute is dependent on only part of a composite key.
example:
STUDENT_COURSE (S#, C#, S_NAME, S_ADDR, C_TITLE, GRADE)
Partial dependencies cannot be tolerated because a table that contains such dependencies is subject to data redundancies and, therefore, to update anomalies. The data redundancies are caused by the fact that every row entry requires a duplication of data.
Solution:
STUDENT (S#, S_NAME, S_ADDR)
STUDENT_COURSE (S#, C#, GRADE)
COURSE (C#, C_TITLE)
Transitive dependency: attribute C is transitively
dependent on attribute A if there is an attribute B such that A ![]() B and B
B and B ![]() C, giving A
C, giving A ![]() C. (Do you remember the Transitive Property of Equality?)
C. (Do you remember the Transitive Property of Equality?)
Also called mutual dependency.
example:
STUDENT_MAJOR (S#, MAJOR_DEPT, DEPT_HEAD)
Assume
S# ![]() MAJOR_DEPT
MAJOR_DEPT
MAJOR_DEPT ![]() DEPT_HEAD
DEPT_HEAD
so...
S# ![]() DEPT_HEAD
DEPT_HEAD
DEPT_HEAD is dependent on S# directly, or transitively through
S# ![]() MAJOR_DEPT
MAJOR_DEPT ![]() DEPT_HEAD
DEPT_HEAD
Partial and transitive dependencies cause anomalies and must be eliminated.
Relations can be broken down to eliminate transitivity and partiality.
Elimination of Transitivity:
STUDENT_MAJOR (S#, MAJOR_DEPT)
DEPT (MAJOR_DEPT, DEPT_HEAD)
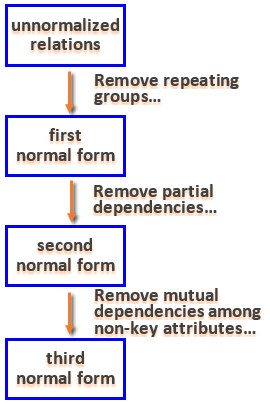
Section 5: Normal Forms
Stages
Normalization can be used to simplify relations.
- Stage 1: unnormalized relations with repeating groups
- Stage 2: first normal form relations
- Stage 3: second normal form relations
- Stage 4: third normal form relations
Normal Forms
First Normal Form (1NF)
- has no repeating groups
- heuristic: if every attribute is atomic (simple or nondecomposable) then the relation is in 1NF
Second Normal Form (2NF)
- all partial dependencies have been removed
- if the relation is in 1NF and every non-key attribute is fully dependent on the key, then the relation is in 2NF
- heuristic: since a partial dependency can exist only if a table's primary key is also a composite key, a table whose primary key consists of only a single attribute is automatically in 2NF if it is in 1NF
Third Normal Form (3NF)
- all transitive dependencies have been removed
- if the relation is in 2NF and there is no transitive, or mutual, dependency among the non-key attributes, then the relation is in 3NF
- heuristic: a transitive dependency is often obvious because one or more attributes seems out of place, that is, it doesn't belong in the relation.
The normalization process follows the steps below:
Recall the original problem from Section 2:
STUDENT_COURSE (S#, S_NAME, COURSE#, C_TITLE, INSTR_NAME, INSTR_OFFICE, GRADE)
- repeating groups: None (1NF)
-
partial dependencies: Yes
STUDENT (S#, S_NAME)
STUDENT_GRADE (S#, C#, GRADE)
COURSE (C#, C_TITLE, INSTR_NAME, INSTR_OFFICE) -
transitive dependencies: Yes
STUDENT (S#, S_NAME)
STUDENT_GRADE (S#, C#, GRADE)
COURSE (C#, C_TITLE, INSTR_NAME)
INSTRUCTOR (INSTR_NAME, INSTR_OFFICE)
Section 6: Normalization Technique
Converting to 1NF (remove repeating groups):
- Recall that if every attribute is nondecomposable then the relation is already in 1NF.
- The repeating group is placed in a new relation (and the attribute upon which the other repeating group attributes were dependent should be designated as a primary key in the new relation).
- The primary key of the original relation becomes an attribute of the new relation in order for them to remain linked.
- If any of the attributes in the new relation are dependent on the linking attribute, then it becomes part of the new primary key; otherwise, it is included as a foreign key.
Converting to 2NF (remove partial dependencies):
- Remember that a table whose primary key consists of only a single attribute is automatically in 2NF if it is in 1NF (since a partial dependency can exist only if a table's primary key is also a composite key)
- If a partial dependency does exist, create new tables that consist of the dependent attributes, associated with a primary key that is obtained from the portion of the original primary key upon which those attributes are dependent.
- Each component of the original primary key, as well as the entire original primary key itself, may potentially be associated with a new table.
Converting to 3NF (remove transitive dependencies):
- Recall that if all the attributes are related to this single entity (with the exception of foreign keys), there should be no transitive dependencies among the non-key attributes
- All attributes involved in the transitive dependency are placed in a new relation, but the attribute upon which the other attributes were dependent should be retained in the original table in order to create a foreign key link to the new table.
Section 7: Normalization Example 1
Problem: Repeating groups (assume multiple organizations are handled)
ACCOUNTS_RECEIVABLE (ORG_ID, BILL_ADDR, DATE_ACCT_OPENED,
(INV#, INV_DATE, INV_AMT),
(CHK#, PMT_DATE, PMT_AMT)
OUTSTANDING_BALANCE, #_ORDERS_TO_DATE)
Step 1: Remove repeating groups.
- The repeating group is placed in a new relation (and the attribute upon which the other repeating group attributes were dependent should be designated as a primary key in the new relation).
- The primary key of the original relation is included in the new relation in order for them to remain linked.
- If any of the attributes in the new relation are dependent on the linking attribute, then it becomes part of the new primary key; otherwise, it is included as a foreign key.
ACCOUNTS_RECEIVABLE (ORG_ID, BILL_ADDR, DATE_ACCT_OPENED,
OUTSTANDING_BALANCE, #_ORDERS_TO_DATE)
INVOICE (INV#, INV_DATE, INV_AMT, ORG_ID)
PAYMENT (CHK#, PMT_DATE, PMT_AMT, ORG_ID)
Decision??
ACCOUNTS_RECEIVABLE (ORG_ID, BILL_ADDR, DATE_ACCT_OPENED,
OUTSTANDING_BALANCE, #_ORDERS_TO_DATE)
INVOICE (INV#, INV_DATE, INV_AMT, ORG_ID)
PAYMENT (CHK#, ORG_ID, PMT_DATE, PMT_AMT)
Step 2: Remove partial dependencies.
ACCOUNTS_RECEIVABLE – OK
INVOICE – OK
PAYMENT – OK
Step 3: Remove transitive dependencies.
ACCOUNTS_RECEIVABLE – OK
INVOICE – OK
PAYMENT – OK
Section 8: Normalization Example 2
Problem: Transitive (mutual) dependencies
BOOK (ISBN, TITLE, AUTHOR, ORG_AFFILIATION, PUBLISHER, PRICE)
Step 1: Remove repeating groups.
BOOK – OK
Step 2: Remove partial dependencies.
BOOK – OK
Step 3: Remove transitive dependencies.
- All attributes involved in the transitive dependency are placed in a new relation, but the attribute upon which the other attributes were dependent should be retained in the original table in order to create a foreign key link to the new table.
ORG_AFFILIATION depends on AUTHOR, which depends on ISBN.
BOOK (ISBN, TITLE, AUTHOR, PUBLISHER, PRICE)
AUTHOR (AUTHOR, ORG_AFFILIATION)
Section 9: Normalization Example 3
Problem: Repeating groups and partial dependencies.
Consider this problem from the perspective of a hardware store – the store assigns part numbers.
SUPPLIER (S#, S_NAME, S_ADDR, (PART#, P_NAME, P_WT))
Step 1: Remove repeating groups.
- The repeating group is placed in a new relation (and the attribute upon which the other repeating group attributes were dependent should be designated as a primary key in the new relation).
- The primary key of the original relation is included in the new relation in order for them to remain linked.
- If any of the attributes in the new relation are dependent on the linking attribute, then it becomes part of the new primary key; otherwise, it is included as a foreign key.
SUPPLIER (S#, S_NAME, S_ADDR)
S_PART (S#, PART#, P_NAME, P_WT)
* intentional mistake
In the solution above we arbitrarily made S# part of the primary key for the new relation without pondering whether it makes sense. Let's see if it still works out.
Step 2: Remove partial dependencies.
- If a partial dependency does exist, create new tables that consist of the dependent attributes associated with a primary key that is obtained from the portion of the original primary key upon which those attributes are dependent.
- Each component of the original primary key, as well as the entire original primary key itself, may potentially be associated with a new table.
PART info should not depend on S#.
SUPPLIER (S#, S_NAME, S_ADDR)
S_PART (S#, PART#)
PART (PART#, P_NAME, P_WT)
Step 3: Remove transitive dependencies.
SUPPLIER – OK
S_PART – OK
PART – OK
Notice that in the example above S_PART is represented as a composite entity.
Section 10: Normalization Example 4
Problem: Normalizing tables rather than schemas.
- A construction company manages several building projects.
- Each project has a project number, name, employees assigned to it, etc.
- Each employee has a number, name, and job classification.
- Clients are billed based on the number of hours spent on the contract, with the hourly billing rate dependent on the employee's position.
-
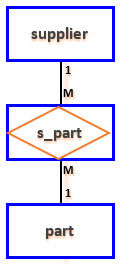
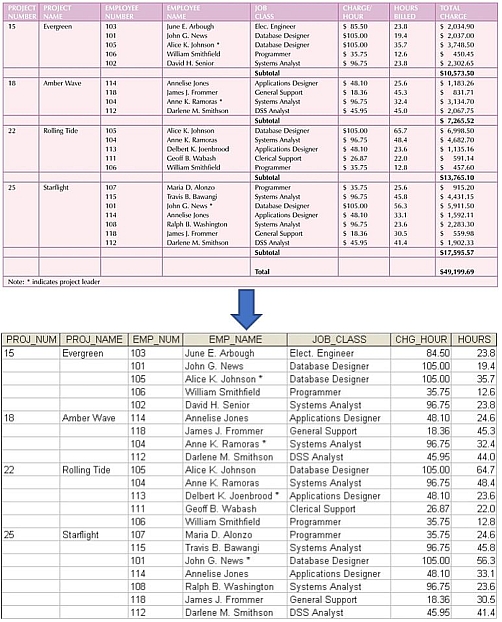
The project status report is shown below.
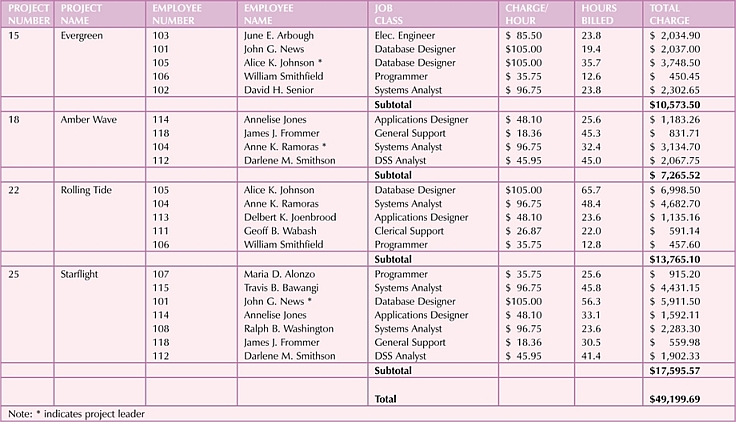
-
The most obvious approach is to have the table design mimic the report, which results in
the following design.
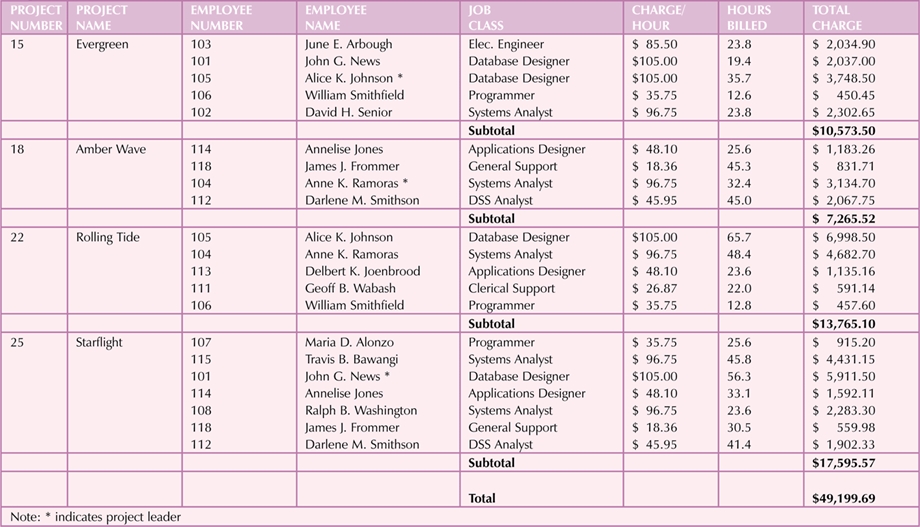
Problems:
- The project number PROJ_NUM is intended to be a primary key, or at least part of a primary key, but it contains null values.
- The table contains data redundancy.
- The table entries invite data inconsistencies. For instance, there are many different ways to abbreviate electrical engineer.
-
The redundancies result in the following anomalies.
- update anomalies – modifying JOB_CLASS requires potentially many alterations.
- addition anomalies – to add a new project, at least one employee must be assigned to it.
- deletion anomalies – if employee 103 quits and is deleted, additional vital data is lost as well.
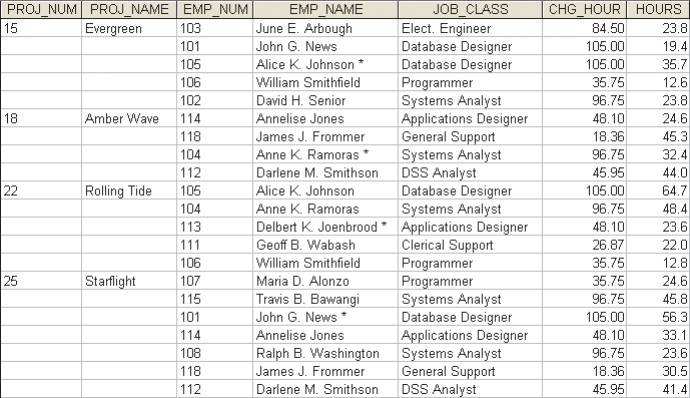
Step 1: Remove repeating groups.
- Each row must define a single entity.
-
process: add the appropriate entry in at least its primary key column.
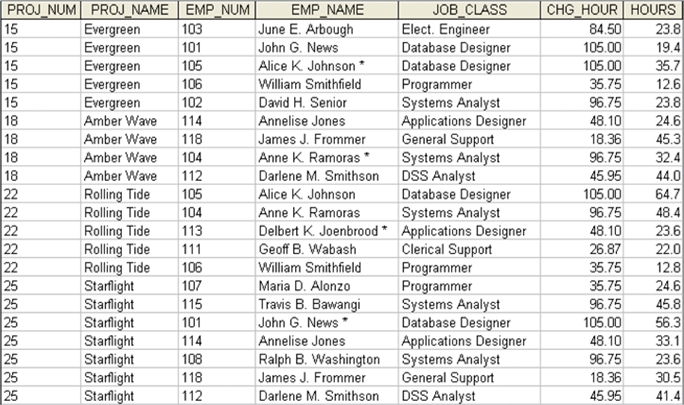
Step 2: Remove partial dependencies.
-
In order to identify dependencies, a dependency diagram, like the figure below, can
be used.
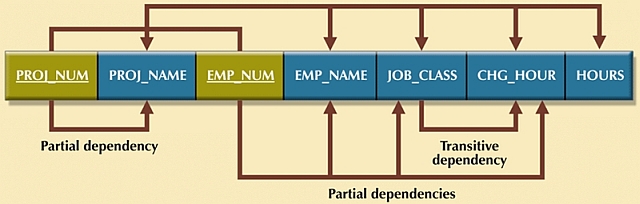
- The arrows above the entity indicate that, in its current form all of the entity's attributes are dependent on the combination of PROJ_NUM and EMP_NUM.
-
Clearly there are partial dependencies in the current design, and the arrows below the entity
are used to indicate dependencies on only part of the
primary key that will need to be addressed.
-
Step 2, Part A: write each of the key components on
separate lines, and then write the original key on the last line.
PROJ_NUM
EMP_NUM
PROJ_NUM EMP_NUM -
Step 2, Part B: write the dependent attributes after each
of the keys, referring to dependency diagram.
PROJECT (PROJ_NUM, PROJ_NAME)
EMPLOYEE (EMP_NUM, EMP_NAME, JOB_CLASS, CHG_HOUR)
ASSIGNMENT (PROJ_NUM, EMP_NUM, ASSIGN_HOURS)
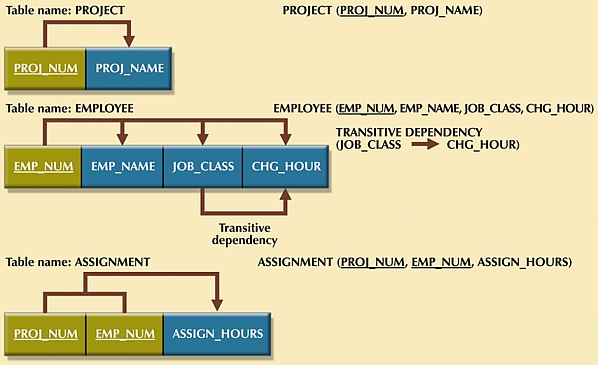
Step 3: Remove transitive dependencies.
- The database anomalies created by the database organization shown in the second diagram in the above figure are easily eliminated by removing the pieces that are identified by the transitive dependency arrows below the dependency diagram and storing them in a separate table.
-
JOB_CLASS is not part of the key and so must be retained in the original 2NF
table in order to establish a link between the original table and the newly
created table.
PROJECT (PROJ_NUM, PROJ_NAME)
ASSIGNMENT (PROJ_NUM, EMP_NUM, ASSIGN_HOURS)
EMPLOYEE (EMP_NUM, EMP_NAME, JOB_CLASS)
JOB (JOB_CLASS, CHG_HOUR)
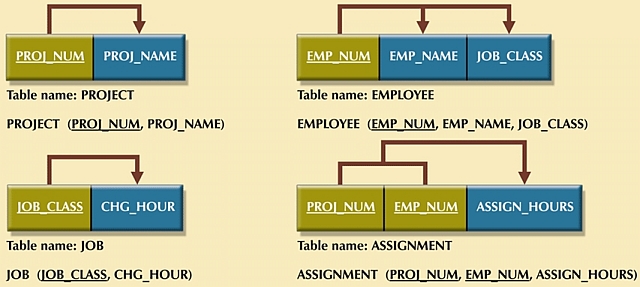
NOTE: Although the four tables are in 3NF, there is a potential problem:
- As the number of employees grows, the JOB_CLASS is entered each time a new employee is entered into the EMPLOYEE table.
- Data entry errors are easy to make.
-
This error can be minimized by creating a JOB_CODE attribute code to serve as the
primary key in the JOB table and as a foreign key in the EMPLOYEE table.
PROJECT (PROJ_NUM, PROJ_NAME)
ASSIGN (PROJ_NUM, EMP_NUM, HOURS)
EMPLOYEE (EMP_NUM, EMP_NAME, JOB_CODE)
JOB (JOB_CODE, JOB_CLASS, CHG_HOUR) -
Does this create a transitive dependency in the JOB table? Not only does
JOB_CODE CHG_HOUR
CHG_HOUR
...but...
JOB_CLASS CHG_HOUR
- However, there is no transitive dependency here because the second determinant – JOB_CLASS – is a candidate key. There are no insertion, deletion, or modification anomalies in this relation; it describes only one entity: the job.
- Note that creating a "better" key is not a case of denormalization. You can read a thorough discussion of denormalization in Denormalization: When, Why, and How.
Section 11: Higher Normal Forms
Third normal form is generally adequate for most situations.
There are higher level normal forms, such as
- Boyce-Codd normal form (BCNF) – every determinant in the table is a candidate key. A determinate is any attribute whose value determines other values within a row. BCNF can be violated only if the table contains more than one candidate key. See Appendix 2.
- Fourth normal form – the table is in 3NF and has no multiple sets of multivalued dependencies. 4NF is "automatic" if all attributes are dependent on the primary key, but independent of each other, and no row contains two or more multivalued facts about an entity. In other words, follow good design and 4NF will result.
- Fifth normal form – A table is in the fifth normal form (5NF) if it cannot have a lossless decomposition into any number of smaller tables. While the first four normal forms are based on the concept of functional dependence, the fifth normal form is based on the concept of join dependence. Join dependency means that a table, after it has been decomposed into three or more smaller tables, must be capable of being joined again on common keys to form the original table. Stated another way, 5NF indicates when an entity cannot be further decomposed. 5NF is complex and not intuitive. Most experts agree that tables that are in the 4NF are also in 5NF except for "pathological" cases. It has been suggested that true many-to-many-to-many ternary relations are one such case. If you want to know more, see this link on Advanced Normalization.
- Domain/key normal form (DKNF) – every constraint on the relations is the result of only two variables: the key and the domains of the non-key attributes. A key is the unique identifier for a record, and a domain (in this case) is the set of allowable values for an attribute. DKNF tells you that every constraint on the domain is a logical result of the key. In other words, each table represents one entity, and all of the business rules are expressed in terms of domain constraints and key relationships. That is, all of the business rules are explicitly described by the table rules. No generalized method for achieving this state has been proposed.