





Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| The student will learn that NoSQL databases are available to store and process Big Data, optimized for data analytics for developing data-driven intelligent applications from Big Data. | The student will be able to list and explain the characteristics of a NoSQL database. |
| The student will be able to list and explain the characteristics of key-value databases. | |
| The student will be able to list and explain the characteristics of document databases. | |
| The student will be able to list and explain the characteristics of column-oriented databases. | |
| The student will be able to list and explain the characteristics of graph databases. | |
| The student will be able to explain how NoSQL databases do not replace relational databases, but simply serve a different purpose. | |
| The student will be able to explain the BASE concept and its implications on NoSQL databases. |
Section 1: Overview
NoSQL - A database management system that is not based on the traditional relational database model.
NoSQL applies to a broad array of nonrelational database technologies that have developed to address the challenges represented by Big Data
- The name was originally a Twitter hashtag to flag discussions about the nonrelational database technologies that were being developed by organizations like Google, Amazon, and Facebook to deal with the problems they were encountering as their data sets reached enormous sizes.
- "NoSQL" does not indicate lack of a query language, nor is concept that the term "NoSQL" stands for "Not Only SQL" correct.
- Many NoSQL products support query languages that mimic SQL in important ways, although there is currently no NoSQL system that implements standard SQL.
- "Not Only SQL" is misleading because if the requirement to be considered a NoSQL product were simply that languages beyond SQL are supported, then all of the traditional RDBMS products would qualify.
Every time you search for a product on Amazon, send messages to friends in Facebook, watch a video on YouTube, or search for directions in Google Maps, you are using a NoSQL database.
NoSQL refers to a new generation of databases that have the following general characteristics, and it's important to understand how these will fit together.
-
They are not based on the relational model and SQL, hence the name NoSQL.
- There is no standard NoSQL data model, but rather many different data models are grouped under the NoSQL umbrella, from document databases to graph stores, column stores, and key-value stores. (More here.)
-
They support distributed database architectures.
- A distributed database consists of a single logical database that is split into a number of fragments, each stored on one or more computers under the control of a separate DBMS, that communicate via a computer network.
- Several NoSQL databases (Cassandra and BigTable, for example) are designed to use commodity servers to form a complex network of distributed database nodes.
-
They provide high scalability, high availability, and fault tolerance.
- NoSQL databases are designed to support web operations, such as the ability to add capacity in the form of nodes to the distributed database when the demand is high, and to do it transparently and without downtime.
- Database scalability focuses on a database's capability of handling growth in data and users, i.e., to increase capacity or add computing nodes based on the workload it is subjected to.
- Fault tolerance means that if one of the nodes in the distributed database fails, it will keep operating as normal.
-
They support very large amounts of sparse data.
- NoSQL databases can handle very high volumes of data.
- They are suited for sparse data—that is, for cases in which the number of attributes is very large but the number of actual data instances is low.
-
They are geared toward performance rather than transaction consistency.
-
One of the biggest problems of very large distributed databases is
enforcing data consistency.
- Distributed databases automatically make copies of data elements at multiple nodes to ensure high availability and fault tolerance.
- If the node with the requested data goes down, the request can be served from any other node with a copy of the data.
- If the network goes down during a data update a relational database must roll back the transaction because transaction updates are guaranteed to be consistent or the transaction is rolled back.
- NoSQL databases sacrifice consistency to attain high levels of performance.
-
Some NoSQL databases provide a feature called eventual consistency,
which means that updates to the database will propagate through the
system and eventually all data copies will be consistent.
- With eventual consistency, data is not guaranteed to be consistent across all copies of the data immediately after an update.
-
One of the biggest problems of very large distributed databases is
enforcing data consistency.
Section 2: Key-Value Databases
Key-value (KV) databases are conceptually the simplest of the NoSQL data models.
A key-value database is a simple database that contains a simple string (the key) that is always unique, and one or more associated arbitrary large data fields (the values).
- The key acts as an identifier for the value.
- The value can be anything such as text, an XML document, or an image.
The key-value data model is also referred to as the attribute-value or associative data model.
The database does not attempt to understand the contents of the value component or its meaning – the database simply stores whatever value is provided for the key.
- It is the job of the applications that use the data to understand the meaning of the data in the value component.
There are no foreign keys; in fact, relationships cannot be tracked among keys at all.
- This greatly simplifies the work that the DBMS must perform, making KV databases extremely fast and scalable for basic processing.
Buckets
Key-value pairs are typically organized into "buckets."
- A bucket can roughly be thought of as the KV database equivalent of a table.
- A bucket is a logical grouping of keys.
- Key values must be unique within a bucket, but they can be duplicated across buckets.
All data operations are based on the bucket plus the key.
- In other words, it is not possible to query the data based on anything in the value component of the key-value pair.
- All queries are performed by specifying the bucket and key.
Operations
Operations on KV databases are rather simple – only get, store, and delete operations are used.
- Get or fetch is used to retrieve the value component of the pair.
-
Store is used to place a value in a key.
- If the bucket + key combination does not exist, then it is added as a new key-value pair.
- If the bucket + key combination does exist, then the existing value component is replaced with the new value.
- Delete is used to remove a key-value pair.
Example 1
The figure below shows a customer bucket with three key-value pairs.

Since the KV model does not allow queries based on data in the value component, it is not possible to query for a key-value pair based on customer last name, for example.
- In fact, the KV DBMS does not even know that there is such a thing as a customer last name because it does not understand the content of the value component.
- An application could issue a get command to have the KV DBMS return the key-value pair for bucket customer and key 10011, but it would be up to the application to know how to parse the value component to find the customer’s last name, first name, and other characteristics.
- Note that the figure is a bit misleading – actual key-value pairs are not stored in a table-like structure.
Example 2
The figure below shows the example of a small truck-driving company called Trucks-R-Us.
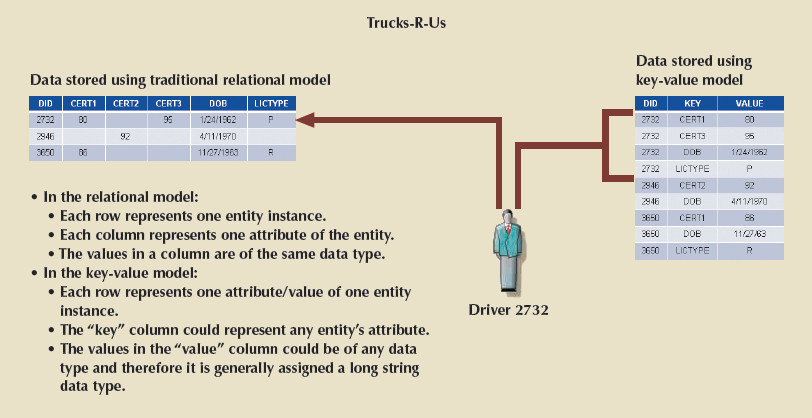
Each of the three drivers has one or more certifications and other general information. Using this example, we can draw the following important points:
- In the relational model, every row represents a single entity occurrence and every column represents an attribute of the entity occurrence. Each column has a defined data type.
- In the key-value data model, each row represents one attribute of one entity instance. The "key" column points to an attribute, and the "value" column contains the actual value for the attribute.
- The data type of the "value" column is generally a long string to accommodate the variety of actual data types of the values placed in the column.
- To add a new entity attribute in the relational model, you need to modify the table definition. To add a new attribute in the key-value store, you add a row to the key-value store, which is why it is said to be "schema-less."
- NoSQL databases do not store or enforce relationships among entities. The programmer is required to manage the relationships in the program code. Furthermore, all data and integrity validations must be done in the program code (although some implementations have been expanded to support metadata).
- NoSQL databases use their own native application programming interface (API) with simple data access commands, such as put, read, and delete. Because there is no declarative SQL-like syntax to retrieve data, the program code must take care of retrieving related data in the correct way.
- Indexing and searches can be difficult. Because the "value" column in the key-value data model could contain many different data types, it is often difficult to create indexes on the data. At the same time, searches can become very complex.
Implementations
Several NoSQL database implementations, such as Google's BigTable and Apache's Cassandra, have extended the key-value data model to group multiple key-value sets into column families or column stores.
- In addition, such implementations support features such as versioning using a date/time stamp.
- For example, BigTable stores data in the syntax of [row, column, time, value], where row, column, and value are string data types, and time is a date/time data type.
- The key used to access the data is composed of (row, column, time), where time can be left blank to indicate the most recent stored value.
Section 3: Document Databases
Document databases are conceptually similar to key-value databases, and they can almost be considered a subtype of KV databases.
A document database is a NoSQL database that stores tagged document-oriented information, also known as semi-structured data, and uses an index to associate "keys" with "documents."
- Unlike a KV database where the value component can contain any type of data, a document database always stores a document in the value component.
- The document can be in any encoded format, such as XML, JSON (JavaScript Object Notation), or BSON (Binary JSON).
Another important difference is that while KV databases do not attempt to understand the content of the value component, document databases do.
- Tags are named portions of a document.
- For example, a document may have tags to identify which text in the document represents the title, author, and body of the document.
- Within the body of the document, there may be additional tags to indicate chapters and sections.
Despite the use of tags in documents, document databases are considered schema-less, that is, they do not impose a predefined structure on the data that is stored.
- For a document database, being schema-less means that although all documents have tags, not all documents are required to have the same tags, so each document can have its own structure.
The tags in a document database are extremely important because they are the basis for most of the additional capabilities that document databases have over KV databases.
- Tags inside the document are accessible to the DBMS, which makes sophisticated querying possible.
Collections
Just as KV databases group key-value pairs into logical groups called buckets, document databases group documents into logical groups called collections.
- While a document may be retrieved by specifying the collection and key, it is also possible to query based on the contents of tags.
Example
The figure below represents the same data as Example 1 above, but in a tagged format for a document database.

- Because the DBMS is aware of the tags within the documents, it is possible to write queries that retrieve all of the documents where the Balance tag has the value 0.
Document databases even support some aggregate functions such as summing or averaging balances in queries.
Additional Details
Document databases tend to operate on an implied assumption that a document is relatively self-contained, not a fragment of the data about a given topic.
- Relational databases decompose complex data in the business environment into a set of related tables.
For example, in a relational database data about orders may be decomposed into customer, invoice, line, and product tables.
- A document database would expect all of the data related to an order to be in a single order document.
- Therefore, each order document in an Orders collection would contain data on the customer, the order itself, and the products purchased in that order all as a single self-contained document.
Document databases do not store relationships as perceived in the relational model and generally have no support for join operations.
Section 4: Column-Oriented Databases
A column-oriented database, also called column family database, is a NoSQL database that organizes data in key-value pairs with keys mapped to a set of columns in the value component.
- While column family databases use many of the same terms as relational databases, the terms don’t mean quite the same things.
-
Column family databases are conceptually simple and are conceptually close
enough to the relational model that your understanding of the relational model
can help you understand the column family model.
- A column is a key-value pair that is similar to a cell of data in a relational database.
-
The key is the name of the column, and the value component is the data
that is stored in that column.
- Therefore, "Lname: Ramas" would be a column; Lname is the name of the column, and Ramas is the data value in the column.
- Similarly, "City: Nashville" is another column, with City as the column name and Nashville as the data value.
-
While a column family is similar in concept to a relational table,
the figure below shows that it is structurally very different.
 Notice in the figure that each row key in the column family can
have different columns.
Notice in the figure that each row key in the column family can
have different columns.
Groups
As more columns are added, it becomes clear that some columns form natural groups, such as Fname, Lname, and Initial which would logically group together to form a customer’s name.
Similarly, Street, City, State, and Zip would logically group together to form a customer’s address.
- These groupings are used to create super columns, which are groups of columns that are logically related.
-
In many cases, super columns can be thought of as the composite attribute
and the columns that compose the super column as the simple attributes.
- Just as all simple attributes do not have to belong to a composite attribute, not all columns have to belong to a super column.
- However, it is possible to group columns into a super column that logically belongs together for application processing reasons but does not conform to the relational idea of a composite attribute.
Row Keys
Row keys are created to identify objects in the environment.
- All of the columns or super columns that describe these objects are grouped together to create a column family; therefore, a column family is conceptually similar to a table in the relational model.
Resources
Section 5: Graph Databases
A graph database is a NoSQL database based on graph theory to store data about relationship-rich environments.
- Graph theory is a well-established mathematical and computer science field that models relationships, or edges, between objects called nodes.
- Modeling and storing data about relationships is the focus of graph databases.
Interest in graph databases originated in the area of social networks.
- Dating websites, knowledge management, logistics and routing, master data management, and identity and access management are all areas that rely heavily on tracking complex relationships among objects.
- In social networking data, there can be dozens of different relationships among individuals that need to be tracked, and often the relationships are tracked many layers deep (e.g., friends, friends of friends, friends of friends of friends, etc.).
- In such situations the relationships become just as important as the data itself, and this is an area in which graph databases excel.
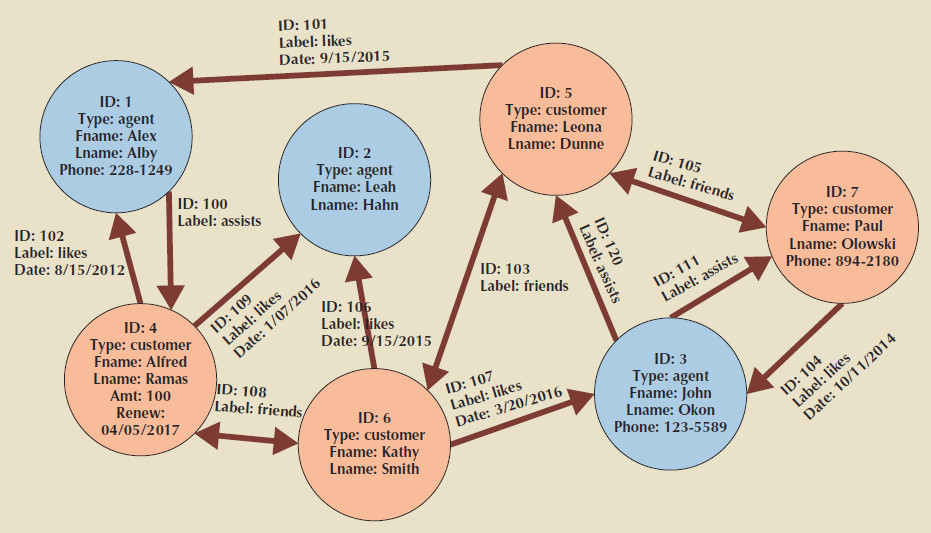
The primary components of graph databases are nodes, edges, and properties as seen in the figure below.
-
A node corresponds to the idea of a relational entity instance.
- The node is a specific instance of something we want to keep data about.
- Each node (circle) in the figure below represents a single agent.
-
Properties are like attributes; they are the data that we need to store about the
node.
- All agent nodes might have properties like first name and last name, but all nodes are not required to have the same properties.
-
An edge is a relationship between nodes.
- Edges (shown as arrows in the figure below) can be in one direction, or they can be bidirectional.
- For example, in the figure below, the friends relationships are bidirectional, but the likes relationships are not.
- Note that edges can also have properties. In the figure below, the date on which customer Alfred Ramas liked agent Alex Alby is recorded in the graph database.
-
A query in a graph database is called a traversal.
- Instead of querying the database, the correct terminology would be traversing the graph.
- Graph databases excel at traversals that focus on relationships between nodes, such as shortest path and degree of connectedness.
Similarities and Differences
Graph databases share some characteristics with other NoSQL databases:
- graph databases do not force data to fit predefined structures.
- graph databases do not support SQ.L
- graph databases are optimized to provide velocity of processing, at least for relationship-intensive data.
However, other key characteristics do not apply to graph databases.
- Graph databases do not scale out very well to clusters
-
The other NoSQL database models achieve clustering efficiency by making each
piece of data relatively independent.
- That allows a key-value pair to be stored on one node in the cluster without the DBMS needing to associate it with another key-value pair that may be on a different node on the cluster.
- The greater the number of nodes involved in a data operation, the greater the need for coordination and centralized control of resources.
- Separating independent pieces of data, often called shards, across nodes in the cluster is what allows NoSQL databases to scale out so effectively.
- Graph databases specialize in highly related data, not independent pieces of data.
- As a result, graph databases tend to perform best in centralized or lightly clustered environments, similar to relational databases.
Resources
Section 6: NewSQL Databases
Relational databases are the mainstay of organizational data, and NoSQL databases do not attempt to replace them for supporting line-of-business transactions.
- These transactions that support the day-to-day operations of business rely on ACID-compliant transactions and concurrency control.
- NoSQL databases (except graph databases that focus on specific relationship-rich domains) are concerned with the distribution of user-generated and machine-generated data over massive clusters.
NewSQL databases try to bridge the gap between RDBMS and NoSQL.
- NewSQL products, such as ClusterixDB and NuoDB, are hybrid products that incorporate features of relational databases and NoSQL databases.
- NewSQL databases attempt to provide ACID-compliant transactions over a highly distributed infrastructure.
- NewSQL databases are the latest technologies to appear in the data management arena to address Big Data problems.
- As a new category of data management products, NewSQL databases have not yet developed a track record of success and have been adopted by relatively few organizations.
Like RDBMS, NewSQL databases support:
- SQL as the primary interface
- ACID-compliant transactions
Similar to NoSQL, NewSQL databases also support:
- Highly distributed clusters
- Key-value or column-oriented data stores
Disadvantages
No technology can perfectly provide the advantages of both RDBMS and NoSQL.
- NewSQL’s heavy use of in-memory storage can jeopardize the "durability" component of ACID.
- The ability to handle vast data sets can be impacted by the reliance on in-memory structures because there are practical limits to the amount of data that can be held in memory.
- Although in theory NewSQL databases should be able to scale out significantly, in practice little has been done to scale beyond a few dozen data nodes, which is far from the hundreds of nodes used by NoSQL databases.
Resources:
Section 7: BASE
If the CAP Theorem accurately states the limitations of distributed databases, how do Google’s BigTable and Amazon’s Dynamo and Facebook’s Cassandra deal with a loss of consistency and still maintain system reliability?
- ACID provides the consistency choice for partitioned databases, but how is availability achieved?
One answer is BASE (basically available, soft state, eventually consistent).
- BASE is diametrically opposed to ACID: Where ACID is pessimistic and forces consistency at the end of every operation, BASE is optimistic and accepts that the database consistency will be in a state of flux.
- Although this sounds impossible to cope with, in reality it is quite manageable and leads to levels of scalability that cannot be obtained with ACID.
-
The availability of BASE is achieved through supporting partial failures without
total system failure.
- Here is a simple example: if users are partitioned across five database servers, BASE design encourages crafting operations in such a way that a user database failure impacts only the 20 percent of the users on that particular host.
- This leads to higher perceived availability of the system.
- This consistency model values availability, but it does not offer guaranteed consistency of replicated data at write time. (See link.)
Basically Available, Soft state, Eventually consistent
-
Basic Availability
- The NoSQL database approach focuses on the availability of data even in the presence of multiple failures.
-
It achieves this by using a highly distributed approach to database management.
- Instead of maintaining a single large data store and focusing on the fault tolerance of that store, NoSQL databases spread data across many storage systems with a high degree of replication.
- In the unlikely event that a failure disrupts access to a segment of data, this does not necessarily result in a complete database outage.
-
Soft State
- The state of the system could change over time, so even during times without input there may be changes going on due to 'eventual consistency,' thus the state of the system is always 'soft.'
- BASE databases abandon the consistency requirements of the ACID model pretty much completely.
- One of the basic concepts behind BASE is that data consistency is the developer's problem and should not be handled by the database.
-
Eventual Consistency
- The only requirement that NoSQL databases have regarding consistency is to require that at some point in the future, data will converge to a consistent state; no guarantees are made, however, about when this will occur.
- That is a complete departure from the immediate consistency requirement of ACID that prohibits a transaction from executing until the prior transaction has completed and the database has converged to a consistent state.
- Eventual consistency informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value.
- See Design Pattern for Eventual Consistency.
The BASE model isn't appropriate for every situation, but it is certainly a flexible alternative to the ACID model for databases that don't require strict adherence to a relational model.
Recap
Databases with BASE consistency model (NoSQL databases) prefers availability over the consistency of replicated data at write time.
- BASE is less strict than ACID.
- Data will be consistent in the future either at the read time or it will be always consistent.
Navigating ACID vs. BASE Trade-offs
There is no right answer to whether an application needs an ACID versus BASE consistency model. Developers and data architects should select their data consistency trade-offs on a case-by-case basis – not based just on what’s trending or what model was used previously.
Given BASE’s loose consistency, developers need to be more knowledgeable and rigorous about consistent data if they choose a BASE store for their application. It's essential to be familiar with the BASE behavior of your chosen aggregate store and work within those constraints.
On the other hand, planning around BASE limitations can sometimes be a major disadvantage when compared to the simplicity of ACID transactions. A fully ACID database is the perfect fit for use cases where data reliability and consistency are essential.
Links
Section 8: Summary
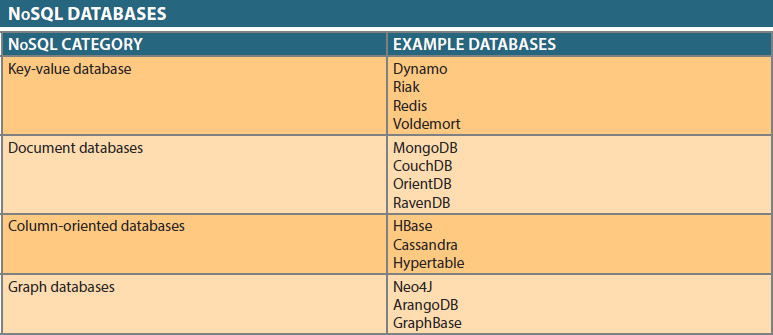
There are literally hundreds of products that can be considered as being under the broadly defined term NoSQL.
- Most of these fit roughly into one of four categories: key-value data stores, document databases, column-oriented databases, and graph databases (and sometimes hybrid cache store databases).
- Although not all NoSQL databases have been produced as open-source software, most have been, so NoSQL databases are generally perceived as a part of the open-source movement.
- Accordingly, they also tend to be associated with the Linux operating system because it is freely available and highly customizable, so most of the NoSQL products run only in a Linux or Unix environment.
The table below shows some popular NoSQL databases of each type.
Section 9: Resources
An Introduction to NoSQL Databases
NoSQL Database Tutorial for Beginners