





Section 1: Definition
The document object model (DOM) is a model for describing and accessing each and every node in an HTML or XML document.
- Because of the DOM, it is possible to access, create, read, change, and delete the nodes that define a typical HTML document.
- The DOM offers complete control over the entire document in order to easily rewrite a page on the fly without the browser making a trip back to the server for new information.
The Document Object Model (DOM) is a specification defining what objects should be available to web page scripting.
- More specifically, the DOM is an application programming interface (API) for representing a document (such as an HTML document) and accessing and manipulating the various elements (such as HTML tags and strings of text) that make up that document.
The DOM allows you to programmatically access and manipulate the contents of a web page (or document).
- It provides a structured, object-oriented representation of the individual elements and content in a page along with methods for retrieving and setting the properties of those objects.
- It also provides methods for adding and removing such objects, allowing you to create dynamic content.
- The DOM makes it possible for JavaScript scripts to inspect or modify a web page dynamically.
- In other words, the DOM is the way JavaScript sees its containing HTML page and browser state.
- The DOM also provides an interface for dealing with events, allowing you to capture and respond to user or browser actions.
W3C definition: "The Document Object Model is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure, and style of documents. The document can be further processed and the results of that processing can be incorporated back into the presented page."
Recall that the DOM underlies and is built upon and manipulated by HTML, CSS, JavaScript and XML to separate presentation from content, as seen in the figure below.
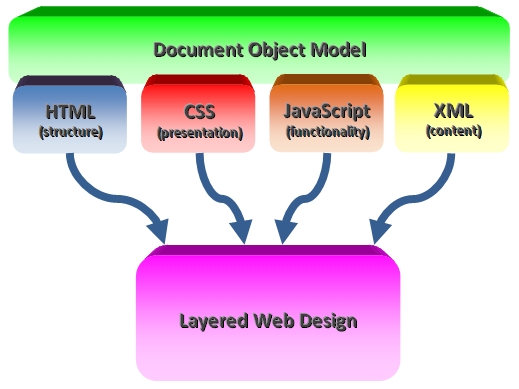
Section 2: Representing Documents as Trees
The W3C DOM, commonly known as 'The DOM' or the 'DOM level 4(or 1/2/3)', provides a more realistic and more versatile way of looking at the structure of HTML documents (as well as XML and other document formats).
- It views HTML documents as a tree structure of elements and text embedded within other elements.
- All HTML elements, as well as the text they contain and their attributes, can be referenced by "walking through" the DOM tree, their contents can be modified or deleted, and new elements can be created for subsequent insertion into the DOM tree.
HTML elements, the text they contain, and their attributes are all known as nodes.
- The tree representation of an HTML document primarily contains nodes representing elements or tags such as <body> and <p> and nodes representing strings of text.
-
Consider the following simple HTML document (with deprecated formatting tags):
<html>
<head>
<title>Sample Document</title>
</head>
<body>
<h1>An HTML Document</h1>
<p>This is a <i>simple</i> document.</p>
</body>
</html>The DOM representation of this document is shown in the tree pictured below.
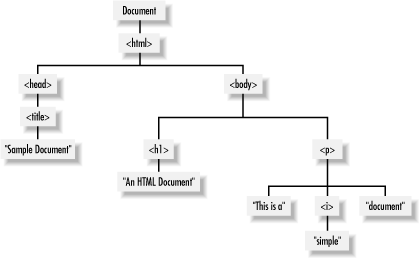
"document" refers to the actual page and content for that page; it is the "top of the tree" and everything else is underneath it.
- For example, the <html> tag is under the document and the <head> tag is under the <html> tag.
Section 3: Tree Example
Below you will find some HTML, followed by a graphic representation of the DOM associated with the HTML.
<!DOCTYPE html>
<html lang="en">
<head>
<link href="domExercise.css" rel="stylesheet" type="text/css" />
<title>DOM Exercise</title>
</head>
<body>
<div>
<img class="floatRight"
src="../2220logoSm.jpg" alt="2220 logo." style="width:35%;" />
<h1>Practice Exercise: DOM</h1>
</div>
<div style="clear:both;">
<hr/>
<p>Objective: To become familiar with DOM representation.</p>
<p>Using the class notes as a guide, create a tree
representation (by hand) of this HTML page.</p>
<hr/>
<a href=../exerciseSolutions/exDOM.htm">Solution</a>
<hr/>
</div>
</body>
</html>
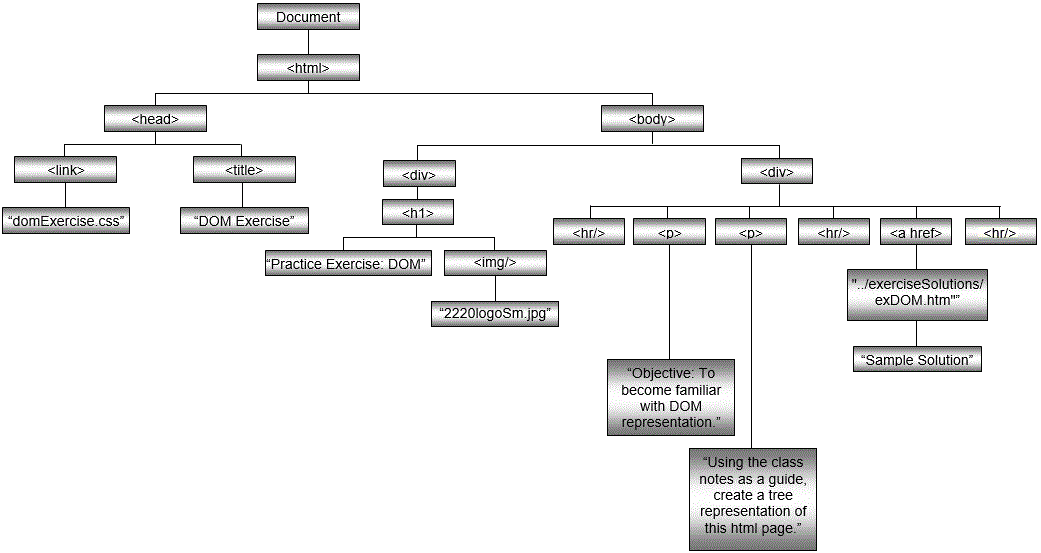
Section 4: Document Interface
Not only does the document object serve as the root of this node tree, it also implements the Document interface, which provides methods for accessing and creating other nodes in the document tree, including:
- getElementById()
- getElementsByTagName()
- createElement()
- createAttribute()
- createTextNode()
Note that unlike other nodes, there is only one document object in a page.
- All of the above methods (except getElementsByTagName()) can only be used against the document object, i.e., using the syntax document.methodName().
Because of the fact that the structure of the DOM tree changes as elements are moved, added, or removed the only reliable way to reference an element is using its id.
- Just remember that each id needs to be unique to the page.
- By adding an id attribute to the paragraph tag (or any tag for that matter), you can reference the tag directly.
<p id="myParagraph">This is a sample paragraph.</p>
.
.
alert(document.getElementById("myParagraph").tagName);
A less direct method to access element nodes is provided by document.getElementsByTagName(), which returns an array of nodes representing all of the elements on a page with the specified HTML tag.
For example, you could change color of every link on a page with the following:
var nodeList = document.getElementsByTagName("a");
for (var i = 0; i < nodeList.length; i++)
nodeList[i].style.color = "#ff0000";
The above code simply updates each link's inline style to set the color to red.
Node Types
As mentioned, there are several types of nodes defined in the document object model, but the ones you'll mostly deal with for web pages are element, text and attribute.
-
Element nodes correspond to individual tags or tag pairs in the HTML code.
- They can have child nodes, which may be other elements or text nodes.
-
Text nodes represent content, or character data.
- They will have a parent node and possibly sibling nodes, but they cannot have child nodes.
-
Attribute nodes are a special case.
-
They are not considered a part of the document tree – they do not have a parent,
children or siblings.
- Instead, they are used to allow access to an element node's attributes.
- That is, they represent the attributes defined in an element's HTML tag, such as the href attribute of the <a> tag or the src attribute on the <img> tag.
-
They are not considered a part of the document tree – they do not have a parent,
children or siblings.
Note that attribute values are always text strings.
Section 5: Walking the DOM
Moving through, or traversing the nodes in the DOM tree structure is often referred to as walking the DOM.
This will be discussed in detail when we reach the section on jQuery methods for traversing the DOM, but if you want more details now, visit any of the following links.
Section 6: Interactivity
Interactivity via Element Attributes (Deprecated)


Interactivity via Style Attributes
Most attributes for HTML tags are fairly simple; they define a single value for a property specific to that tag.
- Styles are a little more involved, since CSS can be used to apply style parameters to an individual tag, all tags of a given type, or assigned to a particular class..
Because the style attribute of an element node is defined as an object with properties for every possible style parameter, you can access and update these individual parameters in response to some event.
Here's an example in which the text alignment is defined and altered using a style parameter.
Here is the code:
<p id="styleDemo">Text in a paragraph element.</p>
<a href="" onclick="document.getElementById('styleDemo').style.textAlign = 'left'; return false;">Align Left</a> |
<a href="" onclick="document.getElementById('styleDemo').style.textAlign = 'right'; return false;">Align Right</a>
Interactivity via Dynamic Content
Changing textual content is relatively simple. Every continuous string of character data in the body of an HTML page is represented by a text node.
-
The nodeValue property of these nodes is the text itself.
- Changing that value will change the text on the page.
Text Nodes
Here's another example using a simple paragraph tag – use the links to change the text:
Now look at the code behind it:
<p id="sample1">This is the initial text.</p>
... code for the links
document.getElementById('sample1').firstChild.nodeValue = 'Once upon
a time...';
document.getElementById('sample1').firstChild.nodeValue = '...in a
galaxy far, far away';
The text nodes do not have an id attribute like element nodes, so they cannot be accessed directly using methods like document.getElementById() or document.getElementsByTagName().
Instead, the code references the text using the parent node, in this case it is the paragraph element with the id "sample1".
This element node has one child node: the text node we want to update, as seen in the diagram below.

So document.getElementById('sample1').firstChild.nodeValue is used to access this text node and read or set its string value.
It is important to remember that text nodes contain just that, text.
- Even simple markup tags like <b> or <i> within a string of text will create a sub tree of element and text nodes.
For example, using the example above and adding tags make the word "initial" bold:
<p id="sample2">This is the <b>initial</b> text.</p>
... code for the links
document.getElementById('sample1').firstChild.nodeValue = 'Once upon
a time...';
document.getElementById('sample1').firstChild.nodeValue = '...in a
galaxy far, far away';
...now gives the "sample2" paragraph element three children instead of one.
- There is a text node for "This is the ", an element node for the <b> tag pair and a text node for " text.".
- The node for the <b> element has one child node: a text node for "initial".
You can see the structure in the diagram below.

The example below demonstrates the code above:
Changing firstChild of the <p> element now only affects the text "This is the ".
Conversely, if you attempt to add markup to the value of a text node, the browser will treat it as plain text.
The changes to the link code seen below:
document.getElementById('sample3').firstChild.nodeValue =
'<b>Once</b> upon a time...';
document.getElementById('sample3').firstChild.nodeValue = '...in a
galaxy <i>far, far</i> away';
...lead to the following results:
You can avoid problems like this by thinking of text nodes as individual strings of character data located between any two HTML tags; not necessarily matching pairs of tags.
But, but... stick with me!
The innerHTML Property
The recently added innerHTML property represents the character data between an element's starting and ending tag, including other HTML tags.
Using this feature, you could replace the entire contents of the sample paragraph element above, including the HTML markup, using something like:
document.getElementById('sample4').innerHtml = "<b>Once</b> upon a time...";
<p id="sample5">This is the <b>initial</b> text.</p>
<a href="" onclick="document.getElementById('sample5').innerHTML = '<b>Once</b> upon a time...'; return false;">Change Text 1</a>
|
<a href="" onclick="document.getElementById('sample5').innerHTML = '...in a galaxy <i>far, far</i> away'; return false;">Change Text 2</a>
And you can see the effect for yourself:
Section 7: Resources
Resources
- Video: Modern JavaScript Tutorial #6 - The Document Object Model
- Video: The DOM: What's the Document Object Model?
- Video: Manipulating the Document Object Model in JavaScript
- Video: Understanding the Document Object Model - 13
- The DOM viewer can be a useful tool.
- Tutorial #1
- Tutorial #2
- Tutorial #3
- Reference
- Browser Object Model