





Section 0: Module Objectives or Competencies
| Course Objective or Competency | Module Objectives or Competency |
|---|---|
| Students will be introduced to some of the theory behind the development of database engines, and will understand the complexity and challenges of developing distributed databases. | The student will be able to explain the definition of a distributed database management system, as well as what features are required in order for a DBMS to be considered distributed. |
| The student will be able to list and explain the components of a DDBMS. | |
| The student will be able to explain that database systems can be classified on the basis of the extent to which process distribution and data distribution are supported. | |
| The student will be able to explain that a DDBMS has various degrees of transparency, which refers to whether the complexities of distribution are noticeable to the user. | |
| The student will be able to explain how database distribution makes concurrent transactions even more complex. | |
| The student will be able to explain how a DDBMS handles transactions that involve data at distributed locations. | |
| The student will be able to explain the implications of database distribution on database design. | |
| The student will be able to explain the CAP Theorem and its implications on distributed databases. | |
| The student will be able to list and explain Date's Commandments for a fully distributed database. |
Section 1: Overview
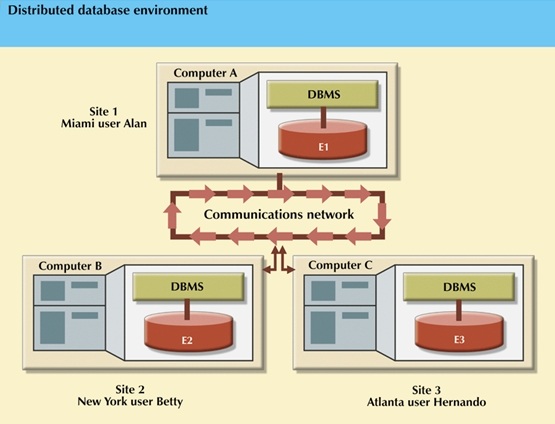
A Distributed Database Management System (DDBMS) consists of a single logical database that is split into a number of fragments, each stored on one or more computers under the control of a separate DBMS, with the computers connected by a communications network.
- Each site is capable of independently processing user requests that require access to local data (that is, each site has some degree of local autonomy) and is also capable of processing data stored on other computers in the network.
- Data is often replicated at multiple sites.
-
Some benefits of distributed databases include the following:
- A DDBMS more accurately reflects the organizational structure.
- A DDBMS improves performance (speed of database access).
- A DDBMS provides a consistent copy of data across all the database nodes.
- A DDBMS increases the availability of data.
- A DDBMS increases the reliability of data in terms of failure recovery.
- A DDBMS improves shareability and local autonomy.
-
A DDBMS improves scalability:
- Scalability focuses on a database's capability of handling growth in data and users, i.e., to increase capacity or add computing nodes based on the workload it is subjected to.
Multi-site database:
- A single database can be divided into several fragments to be stored in different computers within a network.
- Processing can also be dispersed among the different network sites or nodes.
- The multi-site database forms the core of the
distributed database system.
Requirements:
- Although a distributed database management system (DDBMS) involves greater complexity, this complexity should be transparent to the user.
- The distributed database must be treated as a single logical database by the DDBMS.
Justification:
- Immediate data access is crucial in the quick-response decision-making environment.
- The decentralization of management structures based on the decentralization of business units makes decentralized multiple-access and multiple-location databases a necessity.
Section 2: DDBMS
A fully distributed database management system governs both the storage and processing of logically related data over interconnected computer systems in which both data and processing functions are distributed over several sites.
A DDBMS has the following characteristics:
- a collection of logically related shared data
- the data is split into a number of fragments
- fragments may be replicated
- fragments/replicas are allocated to sites
- the sites are linked by a communications network
- the data at each site is under the control of a DBMS
- the DBMS at each site can handle local applications, autonomously
- each DBMS participates in at least one global application
A DBMS must have at least the following functions to be classified as distributed:
- Application interface – to interact with the end user or application program
- Validation – to analyze data requests
- Transformation – to determine requests' components
- Query-optimization – to find the best access strategy
- Mapping – to determine the data location
- I/O interface – to read or write data from or to permanent storage
- Formatting – to prepare the data for presentation to the end user or an application program
- Security – to provide data privacy
- Backup and recovery – to ensure the availability and recoverability of the database in case of failure
- DB administration – for the database administrator
- Concurrency control – to manage simultaneous data access and assure data consistency
- Transaction management – to assure that the data move from one consistent state to another
A fully DDBMS must perform all of the functions of a centralized DBMS, but it must also handle all necessary functions imposed by the distribution of data and processing. These additional functions must be performed transparently to the end user.
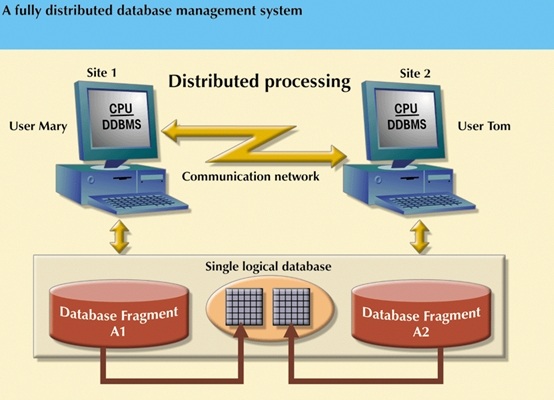
The figure below shows a single logical database that consists of two database fragments A1 and A2 located at sites 1 and 2. The end users see only one logical database. It is irrelevant to the users that the database is divided into two separate fragments or where those fragments reside.
Section 3: DDBMS Components
DDBMS components include
- Computer workstations (sites or nodes) that make up the network.
- Network hardware and software.
- Communications media that carry the data from node to node.
- Transaction processor (TP), which is the software component in each node that receives and processes data requests.
- Data processor (DP), which is the software component in each
node that stores and retrieves data located at the site.
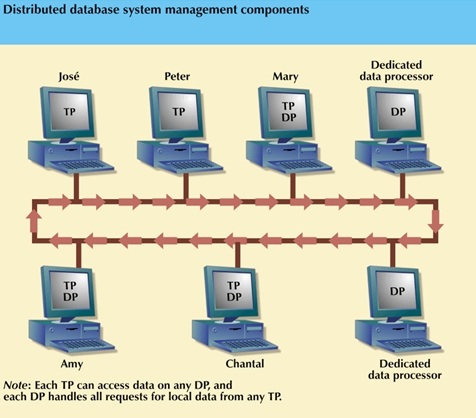
The communication among DPs and TPs is possible through a set of rules or protocols used by the DDBMS.
The protocols determine how the distributed database will:
- Interface with the network to transport data and commands between data processors (DPs) and transaction processors (TPs)
- Synchronize all data received from DPs (TP side) and route retrieved data to the appropriate TPs (DP side)
- Ensure common database functions in a distributed system, such as security, concurrency control, backup, and recovery.
Data processors (DPs) and transaction processors (TPs) can be added to the system without affecting the operation of the other components.
Section 4: Levels Of Data and Process Distribution
Database systems can be classified on the basis of the extent to which process distribution and data distribution are supported.
A DBMS may store data in a single site (centralized DB) or in multiple sites (distributed DB) and may support data processing at a single site or at multiple sites.

SPSD (Single-Site Processing, Single-Site Data)
- All processing is done on a single CPU or host computer and all data are stored on the host computer's disk. Processing cannot be done on the end user's side of the system.
MPSD (Multiple-Site Processing, Single-Site Data)
- Multiple processes run on different computers which share a single data repository. This normally involves a network file server on which conventional applications are accessed through a LAN.
MPMD (Multiple-Site Processing, Multiple-Site Data)
- This describes a fully DDBMS with support for multiple data processors and transaction processors at multiple sites.
Section 5: Distributed Database Transparency Features
A DDBMS requires functional characteristics that can be grouped and described as a set of transparency features, which have the common property of hiding, or making transparent to the user, the complexities of a distributed database.
-
distribution transparency
- allows a distributed database to be treated as a single logical database. The user is unaware that data are partitioned, that data may be replicated at multiple sites, and where data are located.
-
transaction transparency
- allows a transaction to update data at several network sites, and ensures that the transaction will be completed entirely or that it will be aborted, thus maintaining database integrity.
-
failure transparency
- ensures that, even in the event of a node failure, the system will continue to operate. Functions that were to be performed by the lost node will be picked up by other nodes.
-
performance transparency
- allows the system to perform as if it were a centralized DBMS, immune to performance degradation due to its use on a network or due to the network's platform differences. This also ensures that the system will find the most cost-effective path to access remote data.
-
heterogeneity transparency
- allows the integration of several different local DBMSs under a common or global scheme, which is responsible for translating data requests from the common schema to the local DBMS schema.
Section 6: Distribution Transparency
Distribution transparency allows the management of a physically dispersed database as though it were a centralized database.
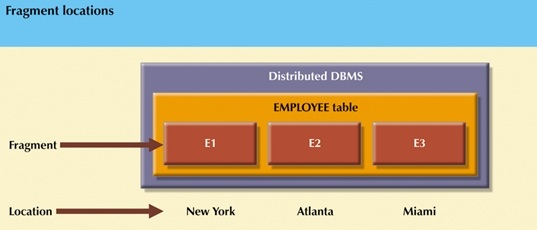
Three levels of distribution transparency are recognized:
-
Fragmentation transparency
- the highest level of transparency
-
The end user or programmer does not need to know that a
database is partitioned. Therefore, neither fragment names nor fragment
locations are specified prior to data access.
SELECT *
FROM EMPLOYEE
WHERE EMP_DOB < '1940-01-01';
-
Location transparency
-
exists when the end user or programmer must specify the database
fragment names but does not need to specify where those fragments
are located.
SELECT *
FROM E1
WHERE EMP_DOB < '1940-01-01';
UNION
SELECT *
FROM E2
WHERE EMP_DOB < '1940-01-01';
UNION
SELECT *
FROM E3
WHERE EMP_DOB < 1940-01-01';
-
exists when the end user or programmer must specify the database
fragment names but does not need to specify where those fragments
are located.
-
Local mapping transparency
-
exists when the end user or programmer must specify both the fragment
names and their locations.
SELECT *
FROM E1 NODE NY
WHERE EMP_DOB < '1940-01-01';
UNION
SELECT *
FROM E2 NODE ATL
WHERE EMP_DOB < '1940-01-01';
UNION
SELECT *
FROM E3 NODE MIA
WHERE EMP_DOB < 1940-01-01';
-
exists when the end user or programmer must specify both the fragment
names and their locations.
Section 7: Transaction Transparency
Transaction transparency ensures that database transactions will maintain the distributed database's integrity and consistency. It ensures that a transaction will be completed only if all database sites involved in the transaction complete their part of the transaction.
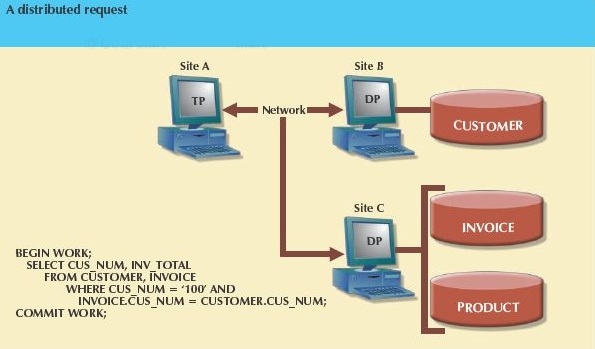
A distributed request allows the user to reference data from several remote DP sites. Since each request can access data from more than one DP site, the transaction can access several sites. The ability to execute a distributed request provides fully distributed database processing capabilities because it allows:
- partitioning of a table into several fragments.
- referencing one or more of those fragments with only one request (fragmentation transparency).
The location and partition of the data should be transparent to the end user.
The figure below shows a distributed request that includes a transaction that uses a single SELECT statement to reference two tables, which are located at different sites.
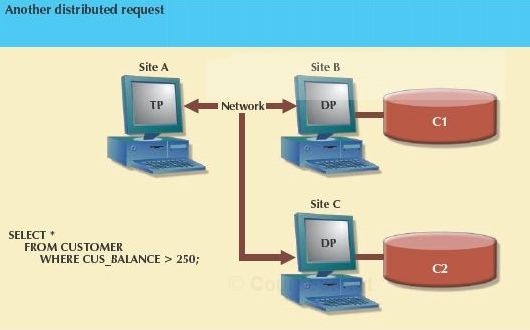
The next figure demonstrates that the distributed request feature allows a single request to reference a physically partitioned table. The CUSTOMER table is divided into two fragments, C1 and C2, located at sites B and C. The user wants a list of all customers whose balances exceed $250.00.
Transaction transparency ensures that distributed transactions are treated as centralized transactions, insuring serializability of transactions. That is, the execution of concurrent transactions, whether or not they are distributed, will take the database from one consistent state to another.
Section 8: Failure Transparency
In a distributed system, failure transparency refers to the extent to which errors and subsequent recoveries of hosts and services within the system are invisible to users and applications.
- For example, if a server fails, but users are automatically redirected to another server and never notice the failure, the system is said to exhibit high failure transparency.
In the distributed environment, the DDBMS must account for:
- the loss of a message
- the failure of a communication link
- the failure of a site
- network partitioning
The DDBMS must ensure the atomicity of each transaction, which means ensuring that subtransactions either all commit or all abort.
- Thus, the DDBMS must synchronize each transaction to ensure that all subtransactions have completed successfully before recording a final COMMIT.
Section 9: Performance Transparency and Query Optimization
Performance transparency mandates that the DDBMS should have a comparable level of performance to a centralized DBMS.
- Query optimizers can be used to speed up response time.
- Optimal database performance with minimal associated costs is the goal of query optimization.
In a distributed environment, the system should not suffer any performance degradation due to the distributed architecture, such as the presence of the network.
Performance transparency also requires the DDBMS to determine the most cost-effective strategy to execute a request.
Most current databases require the user to specify what is required in a query, but not how to acquire it.
-
In a distributed database system, query optimization becomes complicated.
- Data may be fragmented and fragments may be replicated, so in optimizing a query, the DDBMS must also consider which fragment and which copy of the fragment to access as part of its execution strategy.
- Hence, the query processor (QP) must evaluate every data request and find an optimal execution strategy by mapping a data request into an ordered sequence of operations on the local databases, taking into account the fragmentation, replication, and allocation schemas.
-
The QP has to decide:
- which fragment to access
- which copy of a fragment to use, if the fragment is replicated
- which location to use
The DDBMS must also consider the additional processing and communication costs associated with the distribution of data.
- The QP produces an execution strategy that is optimized with respect to some cost function.
-
Typically, the costs associated with a distributed request include
- the access time (I/O) cost involved in accessing the physical data on disk
- the CPU time cost incurred when performing operations on data in main memory
- the communication cost associated with the transmission of data across the network
In a distributed environment, the DDBMS must take account of the communication cost, which may be the most dominant factor in WANs with a bandwidth of a few kilobytes per second.
One approach to query optimization minimizes the total cost of time that will be incurred in executing the query.
An alternative approach minimizes the response time of the query, in which case the QP attempts to maximize the parallel execution of operations.
Section 10: Distributed Concurrency Control
Concurrency control is especially important in a distributed database environment because multi-site, multiple-process operations are much more likely to create data inconsistencies and deadlocked transactions than are single-site systems. All parts of the transaction, at all sites, must be completed before a final COMMIT is issued to record the transaction.
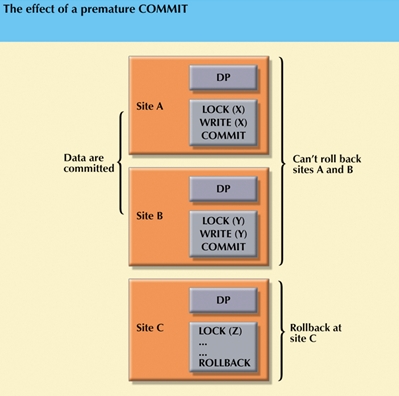
The following figure shows a situation in which each transaction operation is supposed to be committed by each local DP, but one of the DPs can not commit the transaction's results. Such a transaction would yield an inconsistent database, with its inevitable integrity problems, because it is not possible to uncommit committed data. The solution is described next.
Section 11: Two-Phase Commit Protocol
Because distributed databases make it possible for a transaction to access data at several sites, a final COMMIT must not be issued until all sites have committed their parts of the transaction. The two-phase commit protocol guarantees that, if a portion of a transaction operation cannot be committed, all changes made at the other sites participating in the transaction will be undone to maintain a consistent database state.
Each DP maintains its own transaction log. The two-phase commit protocol requires that each individual DP's transaction log entry be written to permanent storage before the database fragment is actually updated. This is referred to as the write-ahead protocol.
The two-phase commit protocol defines the operations between two types of nodes: the coordinator and one or more subordinates. The protocol is implemented in two phases:
Phase 1: Preparation
- The coordinator sends a PREPARE TO COMMIT message to all subordinates.
- The subordinates receive the message, write the transaction log using the write-ahead protocol, and send an acknowledgement to the coordinator (PREPARED TO COMMIT or NOT PREPARED).
- If all nodes are prepared to commit, the coordinator enters phase 2. Otherwise the coordinator will broadcast an ABORT message to all subordinates.
Phase 2: The Final COMMIT
- The coordinator broadcasts a COMMIT message to all subordinates and waits for their replies.
- Each subordinate receives the COMMIT message and proceeds to update the database.
- The subordinates then reply with a COMMITTED or NOT COMMITTED message to the coordinator.
If any of the subordinates does not commit, the coordinator sends an ABORT message, thereby forcing all changes to be rolled back.
The objective of the two-phase commit is to ensure that all nodes commit their part of the transaction, or the transaction is aborted. If one of the nodes fails to commit, then the information necessary to recover the database is in the transaction log, and the database can be recovered.
Section 12: Distributed Database Design
Although the design principles discussed earlier apply equally to distributed databases, designers also need to consider:
- how to partition the database into fragments that can be replicated at different sites, and
- where to locate those fragments.
Data fragmentation and data replication address the first issue, and data allocation deals with the second.
Data Fragmentation
Data fragmentation allows a single object to be broken into two or more segments or fragments.
The object can be a user's database, a system database, or a table.
The fragments can be stored at any node on the network.
Data fragmentation information is stored in the distributed data catalog (DDC), where it is accessed by the transaction processor (TP) to process user requests.
Data fragmentation strategies are based at the table level and consist of dividing a table into logical fragments:
-
Horizontal fragmentation: refers to the division of a relation into subsets
(fragments) of tuples (rows).
- Each fragment is stored at a different node, and each fragment has unique tuples, but the same attributes (columns).
- [Each fragment resembles the equivalent of a SELECT statement, with the WHERE clause on a single variable.]
-
Vertical fragmentation: refers to the division of a relation into attribute
(column) subsets.
- Each subset, or fragment, is stored at a different node, and each fragment has unique columns – with the exception of the key column which is common to all fragments.
- [This is the equivalent of a PROJECT statement.]
- Mixed fragmentation: refers to a combination of horizontal and vertical strategies.
- A table may be divided into several horizontal subsets (rows), each one having a subset of the attributes (columns).
Illustrations

Horizontal Fragmentation
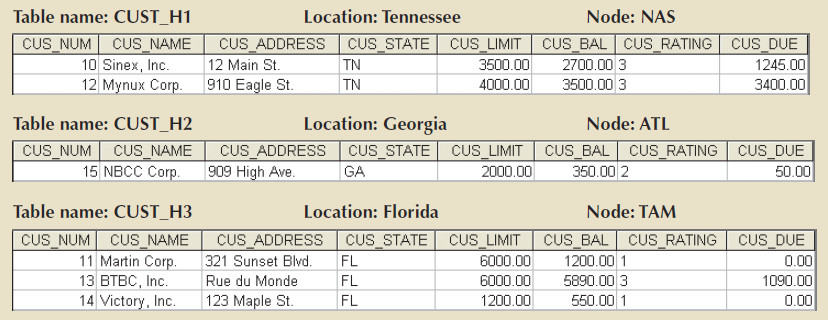
Corporate management requires information about its customers in all three states, but company locations in each state (TN, FL, and GA) require data regarding local customers only.
- Based on such requirements, the data can be distributed by state.
- The horizontal partitions must conform to the structure shown below.
- Each horizontal fragment may have a different number of tuples, but it MUST have the same attributes.

The resulting fragments yield the three tables shown below.
Vertical Fragmentation
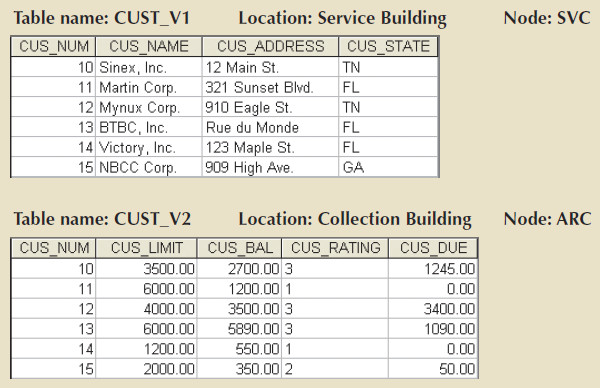
The CUSTOMER relation can also be divided into vertical fragments that are composed of a collection of attributes.
- Assume that the company is divided into two departments: the service department and the collections department.
- Each department is located in a separate building and each has an interest in only a few of the CUSTOMER table's attributes.
- The following table shows how the fragments will be designed. Each vertical fragment must have the same number of tuples, but the inclusion of the different attributes depends on the key column.

The vertical fragmentation results are shown below.
Mixed Fragmentation
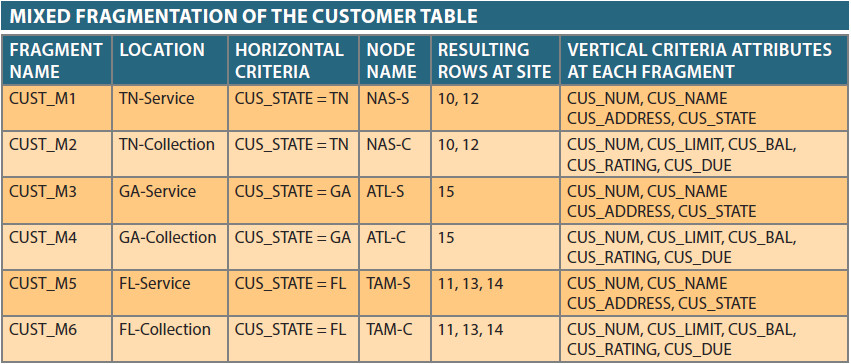
Mixed fragmentation requires both horizontal and vertical table partitioning.
- Assume that the company operates from all three locations, and at each location the two departments are located in different buildings.
- Each department requires access to information about local customers.
- Thus, the data must be fragmented horizontally to accommodate the different locations, and within the locations the data must be fragmented vertically to accommodate the different departments.
Mixed fragmentation requires a two-step procedure
- First, horizontal fragmentation is introduced for each site, based on the location within the state. This horizontal fragmentation yields the subsets of customer tuples (horizontal fragments) that will be located at each site.
- Since the departments are located in different buildings, vertical fragmentation is applied to each horizontal fragment to divide the attributes, thus providing for each department's information needs at each subsite.
The mixed fragmentation yields the results shown below.
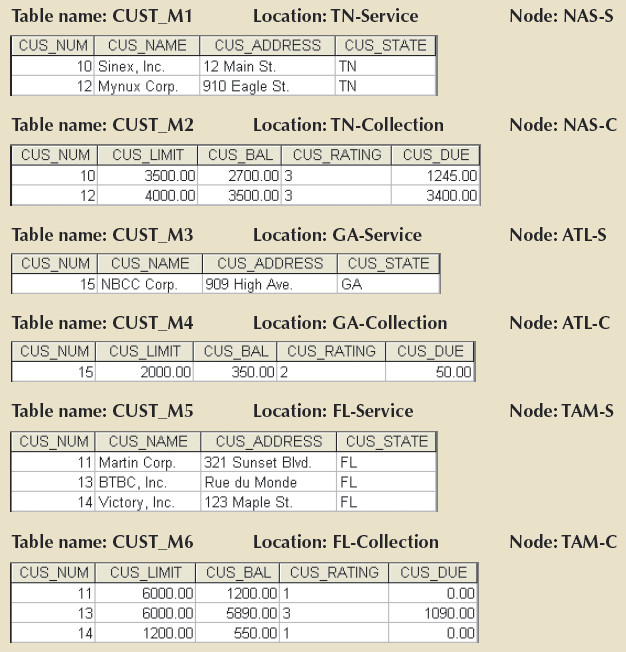
Each of the fragments shown above contains customer data by state and, within each state, by department location, to fit each department's requirements. The tables corresponding to the fragments are data shown below.
Data Replication
Data replication refers to the storage of data copies at multiple sites.
Fragment copies may be stored at several sites to serve specific information requirements (and to provide some degree of redundancy in the event that a node goes down).
Since the existence of fragment copies may enhance data availability and response time, they help to reduce both communication costs and total query costs.
Suppose database A is divided into fragments A1 and A2. Within a replicated distributed database the scenario depicted below is possible. Fragment A1 is stored at sites S1 and S2, while fragment A2 is stored at sites S2 and S3.

Replicated data are subject to the mutual consistency rule, which requires that all data fragments must be identical. To maintain data consistency among the replicas, the DDBMS must ensure that a database update is performed at all sites where the replicas exist.
Despite the advantages associated with replication, it also requires additional processing overhead, because each of the data copies must be maintained by the system. The DDBMS must perform the following processes on the system:
- If the database is fragmented, it must decompose a query into subqueries to access the appropriate fragments.
- If the database is replicated, it must decide which copy to access. A READ operation selects the nearest copy to satisfy the transaction. A WRITE transaction requires that all copies must be selected and updated to satisfy the mutual consistency rule.
- The TP sends a data request to each DP for execution.
- The DP receives and executes each request and sends the data back to the TP.
- The TP merges the DP responses.
Three replication conditions exist:
- A fully replicated database stores multiple copies of each database fragment at multiple sites. All database fragments will be replicated, which tends to be impractical due to the amount of overhead that it will impose on the system.
- A partially replicated database stores multiple copies of some database fragments at multiple sites. Partial replication does not demand excessive overhead and so is practical.
- A database that is not replicated stores each fragment at a single site only, so there are no duplicate fragments.
Two factors influence data replication: usage frequency and database size. When the usage frequency of remotely located data is high and the database is large, replication is likely to reduce the cost of data requests.
Data Allocation
Data allocation refers to the process of deciding where to locate data. Data allocation is closely related to the way a database is divided or fragmented.
Data allocation algorithms take into consideration a variety of factors:
- Performance and data availability goals.
- Size, number of rows, and the number of relations that an entity maintains with other entities.
- Types of transactions to be applied to the database, the attributes accessed by each of those transactions, etc.
Section 13: CAP Theorem
In 2000, Eric Brewer presented the CAP Theorem, which states that there are three essential system requirements necessary for the successful design, implementation, and deployment of applications in distributed computing systems – Consistency, Availability, and Partition Tolerance – but in the majority of instances, a distributed system can only guarantee two of the three features.
- Consistency – A guarantee that every node in a distributed cluster returns the same, most recent, successful write. Consistency refers to every client having the same view of the data.
- Availability - Every non-failing node returns a response for all read and write requests in a reasonable amount of time. To be available, every node on (either side of a network partition) must be able to respond in a reasonable amount of time.
- Partition Tolerant - The system continues to function and upholds its consistency guarantees in spite of network partitions. Network partitions are unavoidable. Distributed systems guaranteeing partition tolerance can gracefully recover from partitions once the partition heals.
The correct way to think about CAP is that in case of a network partition one needs to choose between availability and consistency.
Links
Section 14: Client/Server Architecture
Many database vendors refer to distributed databases as client/server.
Client/server architecture actually refers to the way in which computers interact to form a system.
- The client/server architecture involves a user of resources (client) and a provider of resources (server).
- A client/server architecture can be used to implement a DBMS in which the client is the TP and the server is the DP.
Section 15: Date's Commandments
C.J. Date provided a list of commandments for a fully distributed database in 1987. While no current DDBMS conforms to all of them, they describe the ideal or eventual target system.
-
Rule 1 Local Site Independence
- Each local site can act as an independent, autonomous, centralized DBMS. Each site is responsible for security, concurrency control, backup, and recovery.
-
Rule 2 Central Site Independence
- No site in the network relies on a central site or any other site. All sites have the same capabilities.
-
Rule 3 Failure Independence
- The system is not affected by node failures. The system is in continuous operation even in the event of a node failure or an expansion of the network.
-
Rule 4 Location Transparency
- The user does not need to know the location of data in order to retrieve those data.
-
Rule 5 Fragmentation Transparency
- The user sees only one single logical database. Data fragmentation is transparent to the user, and the user does not need to know the name of the database fragments to retrieve them.
-
Rule 6 Replication Transparency
- The user sees only one single logical database. The DDBMS transparently selects the database fragment to access, and manages all fragments transparently to the user.
-
Rule 7 Distributed Query Processing
- A distributed query may be executed at several different DP sites. Query optimization is performed transparently by the DDBMS.
-
Rule 8 Distributed Transaction Processing
- A transaction may update data at several different DP sites. The transaction is transparently executed at several different DP sites.
-
Rule 9 Hardware Independence
- The system must run on any hardware platform.
-
Rule 10 Operating System Independence
- The system must run on any operating-system software platform.
-
Rule 11 Network Independence
- The system must run on any network platform.
-
Rule 12 Database Independence
- The system must support any vendor's database product.